Chapter4: Network Layer-Data Plane
Network Layer services and protocols
- 송신 호스트에서 수신 호스트로의 전송 세그먼트
- 송신자
- 세그먼트를 데이터그램으로 캡슐화한다.
- 데이터그램을 링크 계층으로 전달한다.
- 수신자
- 세그먼트를 전송 계층 프로토콜로 전달한다.
- 송신자
- 모든 인터넷 장치(호스트, 라우터)에서의 네트워크 계층 프로토콜
- 네트워크 계층 프로토콜은 모든 인터넷 장치(호스트와 라우터)에 존재한다.
- 라우터의 역할
- 라우터는 IP 데이터그램의 헤더 필드를 검사한다.
- 라우터는 데이터그램을 입력 포트에서 출력 포트로 이동시켜 데이터그램이 끝에서 끝으로 전송될 수 있도록 한다.

Two key network-layer functions
네트워크 계층 기능
- 포워딩(Forwarding)
- 역할: 라우터의 입력 링크에서 적절한 출력 링크로 패킷을 이동시키는 과정이다.
- 비유: 고속도로의 한 교차로를 통과하는 과정이라고 생각할 수 있다.
2. **라우팅(Routing)** - 역할: 출발지에서 목적지까지 패킷이 이동할 경로를 결정하는 과정 - 라우팅 알고리즘을 사용하여 경로를 결정 - 비유: 출발지에서 목적지까지의 여행 계획을 세우는 과정으로 생각할 수 있다.
Network layer: data plane, control plane
데이터 플레인(Data Plane)
- 로컬, 라우터별 기능
- 데이터 플레인은 각 라우터에서 로컬로 작동하는 기능이다.
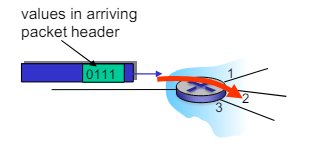
- 라우터의 입력 포트에서 도착한 데이터그램이 라우터의 출력 포트로 어떻게 전달될지를 결정한다.
- 예시 그림에서는 도착한 패킷 헤더의 값을 기반으로 데이터그램이 어떻게 전달되는지를 보여준다.
컨트롤 플레인(Control Plane)
- 네트워크 전체의 논리
- 컨트롤 플레인은 네트워크 전체에서 작동하는 논리이다.
- 데이터그램이 출발지 호스트에서 목적지 호스트까지 여러 라우터를 통해 어떻게 라우팅될지를 결정한다.
- 두 가지 컨트롤 플레인 접근 방식이 있다.
- 전통적인 라우팅 알고리즘(Tranditional Routing Algorithms): 라우터에서 구현된다.
- 소프트웨어 정의 네트워킹(Software-Defined Networking: SDN): (원격) 서버에 구현된다.
Per-router control plane
라우터별 컨트롤 플레인
- 각 라우터에는 독립적인 라우팅 알고리즘이 있다.
- 이 라우팅 알고리즘은 라우터 간의 상호 작용을 통해 네트워크 전체의 데이터를 관리한다.
컨트롤 플레인과 데이터 플레인의 상호작용
- 슬라이드의 그림은 컨트롤 플레인과 데이터 플레인의 구조를 보여준다.
- 컨트롤 플레인: 네트워크의 상위 레벨에서 라우터 간의 경로를 결정하는 데 사용된다.
- 데이터 플레인: 각 라우터에서 패킷이 실제로 이동하는 경로를 처리한다.
라우팅 알고리즘
- 각 라우터에는 라우팅 알고리즘이 구현되어 있다.
- 이 알고리즘은 도착하는 패킷의 헤더 값을 기반으로 로컬 포워딩 테이블을 참조하여 적절한 출력 포트를 결정한다.
로컬 포워딩 테이블
- 라우터의 로컬 포워딩 테이블은 도착하는 패킷 헤더 값과 그에 대응하는 출력 포트를 나타낸다.
- 예를 들어, 헤더 값 0100은 출력 포트 3으로 설정되어 있다.
Software-Defined Networking(SDN) control plane
SDN은 네트워크의 데이터 흐름을 중앙에서 제어할 수 있도록 하는 접근 방식이다.
- 원격 컨트롤러(Remote Controller)
- 원격 컨트롤러는 라우터의 포워딩 테이블을 계산하고 설치한다.
- 이는 네트워크의 중앙 집중식 관리와 제어를 가능하게 한다.
- 포워딩 테이블 설치
- 원격 컨트롤러는 각 라우터에 포워딩 테이블을 설치한다.
- 이는 네트워크 전체의 데이터 흐름을 효과적으로 관리할 수 있게 한다.
- 컨트롤 플레인과 데이터 플레인의 구분
- 컨트롤 플레인은 라우터 간의 경로를 결정하고 관리한다.
- 데이터 플레인은 실제로 패킷이 이동하는 경로를 처리한다.
Network Service Model
Q. 송신자에서 수신자로 데이터그램을 전송하는 "채널"에 대한 서비스 모델은 무엇인가?
개별 데이터그램을 위한 서비스 예시
- 보장된 전달(Guaranteed Delivery)
- 데이터그램이 반드시 목적지에 도달할 것을 보장한다.
- 40밀리초 이하의 지연으로 보장된 전달(Guaranteed Delivery with Less Than 40 msec Delay)
- 데이터그램이 40밀리초 이하의 지연으로 목적지에 도달할 것을 보장한다.
데이터그램 흐름을 위한 서비스 예시
순서대로 데이터그램 전달(in-order Datagram Delivery)
- 데이터그램이 전송된 순서대로 도착하도록 보장한다.
흐름에 대한 최소 대역폭 보장(Guranteed Minimum Bandwidth to Flow)
- 특정 흐름에 대한 최소한의 대역폭을 보장한다.
패킷 간 간격 변화에 대한 제한(Restrictions on Changes in INter-packet Spacing)
- 패킷 간 간격의 변화를 제한하여 일정한 간격으로 데이터그램이 전달되도록 한다.
인터넷 Best Effort 서비스 모델
- 인터넷의 Best Effort 서비스 모델은 데이터그램의 전달을 최선의 노력으로 수행하지만, QoS 측면에서 어떠한 보장도 제공하지 않는다.
- Best Effort 모델에서는 다음과 같은 사항에 대해 보장이 없다
- 성공적인 데이터그램 전달(Successful Datagram Delivery)
- 전달의 타이밍 또는 순서(Timing or Order of Delivery)
- 종단 간 흐름에 사용 가능한 대역폭(Bandwidth Available to End-to-End Flow)

Relections on best-effort service
Best-Effort 서비스 모델이 인터넷의 널리 채택되고 왜 성공하는 가?
간단한 메커니즘(Simplicity of Mechanism)
- Best-Effort 서비스 모델의 단순함은 인터넷이 널리 배포되고 채택될 수 있도록 했다.
- 복잡하지 않은 구조로 인해 구현과 관리가 용이
충분한 대역폭 제공
- 충분한 대역폭이 제공되면 실시간 어플리케이션(e.g. 통화, 비디오)의 성능이 대부분의 경우에 "충분히 좋은" 상태를 유지할 수 있다.
- 이는 Best-Effort 모델에서도 실시간 서비스가 어느 정도 품질을 유지할 수 있음을 의미한다.
분산된 어플리케이션 계층 서비스
- 데이터 센터와 컨텐츠 배포 네트워크(CDN)와 같은 분산된 어플리케이션 계층 서비스는 클라이언트 네트워크에 가깝게 연결되어 있다.
- 이러한 서비스는 여러 위치에서 제공될 수 있어 사용자가 더 나은 서비스를 받을 수 있다.
"Elastic" 서비스의 혼잡제어
- 탄력적인 서비스의 혼잡 제어는 네트워크의 혼잡을 관리하고 전체 성능을 향상시키는 데 도움이 된다.
Router architecture overview
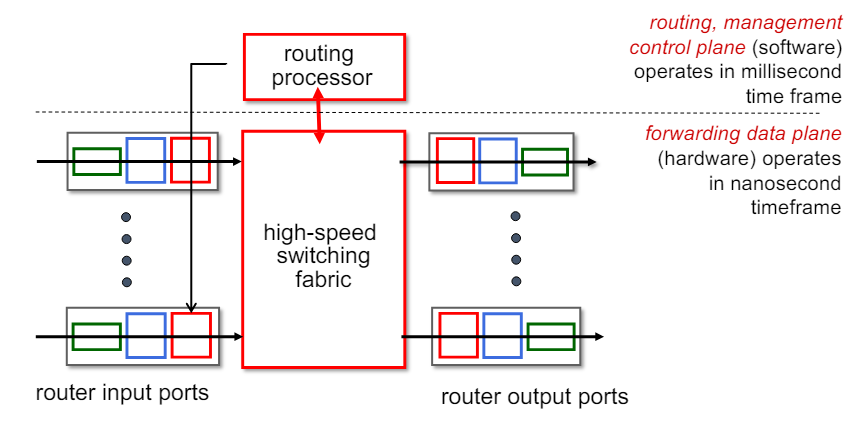
라우터 입력 포트(Router Input Ports)
- 데이터그램이 라우터에 들어오는 포트이다.
- 각 입력 포트는 패킷을 처리하고, 올바른 출력 포트로 전달하기 위해 준비한다.
고속 스위칭 패브릭(Hight-Speed Switching Fabric)
- 입력 포트에서 출력 포트로 패킷을 전달하는 고속 스위칭 메커니즘이다.
- 이 패브릭은 매우 짧은 시간(나노초 단위) 내에 패킷을 전달할 수 있다.
라우터 출력 포트(Router Output Ports)
- 데이터그램이 라우터를 떠나 목적지로 향하는 포트이다.
- 출력 포트는 패킷을 최종 목적지로 전달하기 위해 준비한다.
라우팅 프로세서(Routing Processor)
- 라우팅의 라우팅 및 관리 기능을 수행하는 프로세서이다.
- 소프트웨어적으로 구현되며, 밀리초 단위의 시간 프레임 내에서 동작한다.
두 가지 주요 플레인
포워딩 데이터 플레인(Forwarding Data Plane)
- 하드웨어적으로 구현되어 있다.
- 패킷이 입력 포트에서 출력 포트로 이동하는 과정을 처리한다.
- 나노초 단위의 시간 프레임 내에서 매우 빠르게 동작한다.
라우팅 및 관리 컨트롤 플레인(Routing and Management Control Plane)
- 소프트웨어 적으로 구현되어 있다.
- 네트워크의 라우팅 경로를 결정하고, 관리 기능을 수행한다.
- 밀리초 단위의 시간 프레임 내에서 동작한다.
Input port functions
- 라인 종단(Line Termination)
- 물리 계층(Physical Layer)
- 비트 수준의 수신을 처리한다.
- 전송 매체로부터 신호를 수신하고 이르 디지털 비트 스트림으로 변환한다.
- 물리 계층(Physical Layer)
- 링크 계층 프로토콜(Link Layer Protocol)
- 링크 계층(Link Layer)
- e.g. 이더넷
- 수신된 프레임을 처리하고, 네트워크 계층으로 데이터를 전달한다.
- 링크 계층(Link Layer)
- Loopup, Forwarding, Queueing
- 탈중앙화 스위칭(Decentralized Switching)
- 헤더 필드 값을 사용하여 입력 포트 메모리에 있는 포워딩 테이블을 조회해 출력 포트를 찾는다. 이를 "match plus action"이라고 한다.
- 목표는 line speed에서 입력 포트 처리를 완료하는 것이다.
- destination-based forwarding: destination IP address를 기반으로 forward하는 것(전통적)
- generalized forwarding: header field 값을 기반으로 forword하는 것
- Input Port Queueing
- 데이터그램이 스위칭 패브릭으로 전달되는 속도보다 더 빨리 도착하면 큐에 저장된다.
- 이를 통해 혼잡을 방지하고 데이터그램 손실을 최소화한다.
- 탈중앙화 스위칭(Decentralized Switching)
Destination-based forwarding
포워딩 테이블 구조
목적지 주소 범위(Destination Address Range)
- 라우터는 도착하는 패킷의 목적지 주소를 기반으로 출력 링크 인터페이스를 결정한다.
- 각 범위는 특정 링크 인터페이스로 매핑된다.
링크 인터페이스(Link Interface)
- 특정 목적지 주소 범위에 해당하는 출력 포트
Q. 만일 주소범위가 제대로 나눠지지 않는다면?
- 포워딩 테이블에서 주소 범위가 겹치거나 깔끔하게 나누어지지 않으면 특정 목적지 주소가 여러 범위에 속할 수 있다.
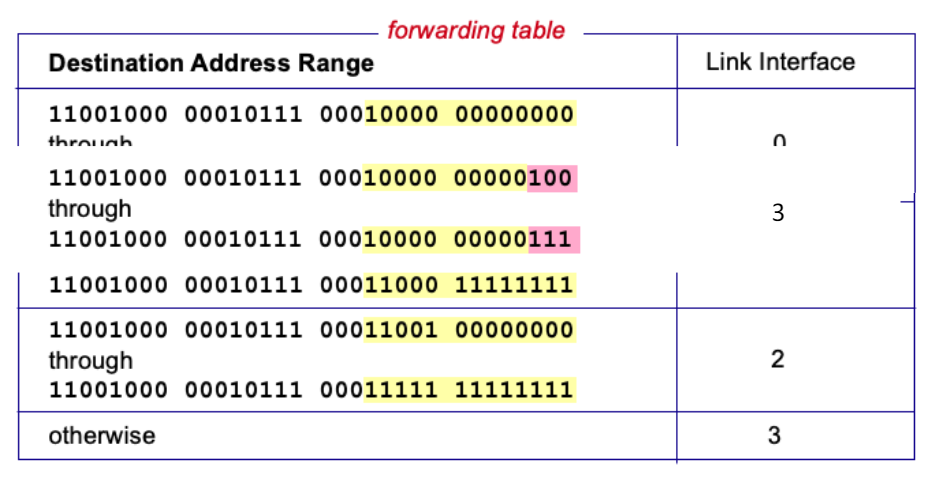
Longest prefix matching
라우터가 목적지 주소에 대해 포워딩 테이블 항목을 찾을 때 사용하는 최장 접두사 일치(Longest Prefix Match) 메커니즘을 설명한다.
정의: Longest Prefix Match
- 주어진 목적지 주소에 대해 포워딩 테이블 항목을 찾을 때, 가장 긴 주소 접두사와 일치하는 항목을 사용한다.

위의 예에서 link interface는 0과 1이다.
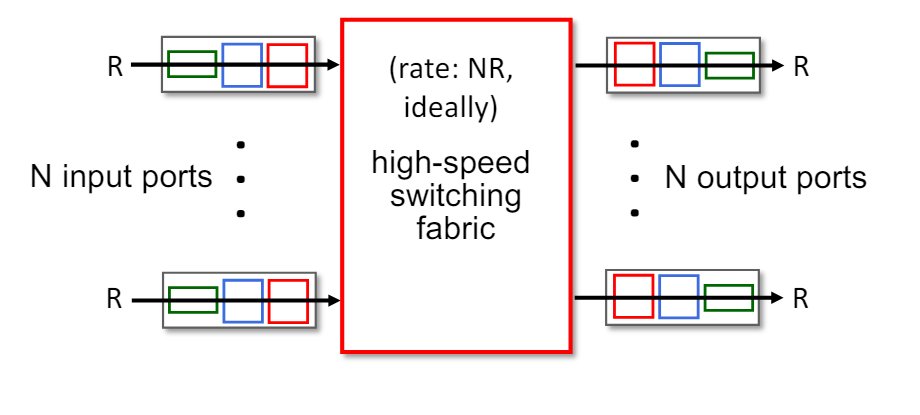
Switching fabric
- 스위칭 패브릭의 역할
- 입력 링크에서 적절한 출력 링크로 패킷을 전송한다.
- 이는 라우터 내부에서 데이터가 효율적으로 전달되도록 한다.
- 스위칭 속도(Switching Rate)
- 패킷이 입력에서 출력으로 전송되는 속도이다.
- 종종 입력/출력 라인 속도의 배수로 측정된다.
- 예를 들어, N개의 입력 포트가 있는 경우, 이상적인 스위칭 속도는 라인 속도의 N배이다.
- 이는 라우터가 동시에 여러 입력 포트에서 들어오는 패킷을 처리할 수 있도록 하기 위함이다.
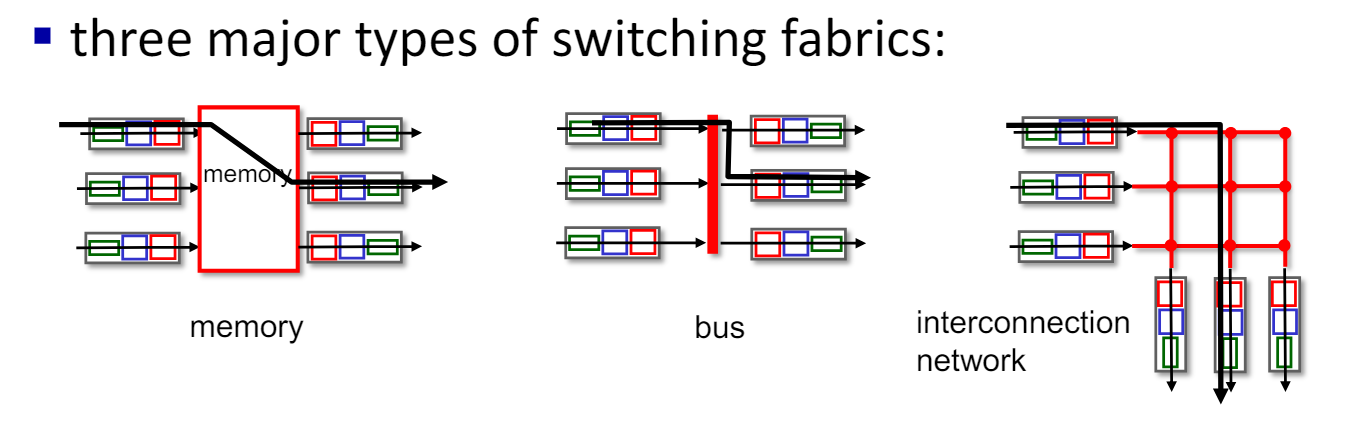
Switching via memory
- 초기 세대 라우터(First Generation Routers)
- 전통적인 컴퓨터 구조: 스위칭이 CPU의 직접적인 제어 하에 이루어진다.
- 패킷 복사: 패킷은 시스템의 메모리에 복사된다.
- 속도 제한:
- 메모리 대역폭에 의해 속도가 제한된다.
- 각 데이터그램당 두 번의 버스 교차가 발생한다.
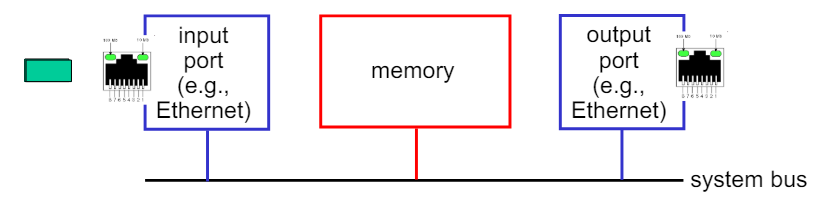
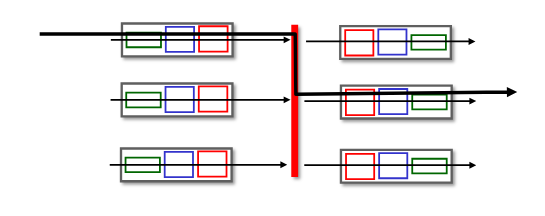
Switching via a bus
버스를 통한 데이터그램 전송
- 입력 포트 메모리에서 출력 포트 메모리로 데이터그램을 전송하는 과정이 공유된 버스를 통해 이루어진다.
버스 경합(Bus Contention)
- 스위칭 속도는 버스 대역폭에 의해 제한된다.
- 여러 포트가 동시에 버스를 사용하려고 하면 버스 경합이 발생하여 스위칭 속도가 감소할 수 있다.
32 Gbps 버스
- e.g. Cisco 5600 라우터는 32 Gbps의 버스를 사용하여 액세스 라우터로서 충분한 속도를 제공한다.
Switching via interconnection network
- 크로스바(CrossBar), 클로스(Clos) 네트워크:
- 이러한 상호 연결 네트워크는 원래 멀티프로세서 시스템에서 프로세서를 연결하기 위해 개발되었다.
- 라우터에서도 사용되어 고속 스위칭을 가능케 한다.
- 다단계 스위치(Multistage Switch)
- 다단계 스위치는 n * n 스위치로, 여러 단계의 작은 스위치들로 구성된다.
- 예를 들어, 8 * 8 스위치는 더 작은 크기의 스위치들로 구성되어 있다.
- 병렬성 활용(Expoiting Parallelism)
- 데이터그램을 고정 길이 셀로 분할하여 입력한다.
- 이 셀들은 패브릭을 통해 스위칭되고, 출구에서 다시 데이터그램으로 재조립된다.
- 병렬 처리를 통해 스위칭 성능을 향상시킬 수 있다.
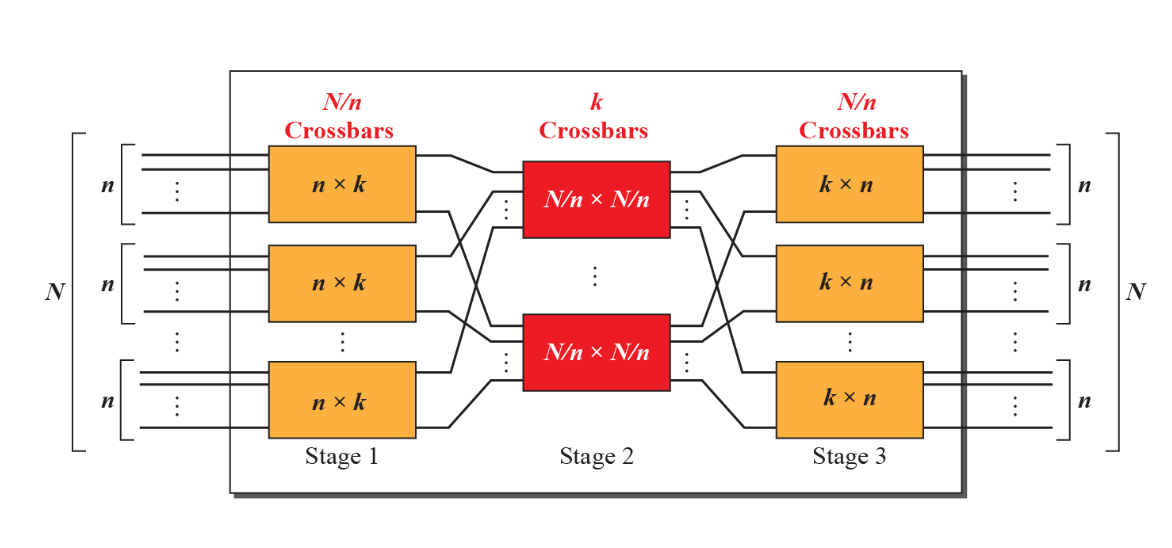
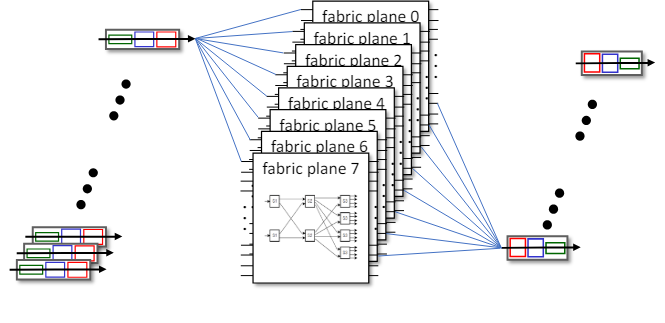
Switching via interconnection network
주요 내용:
- 확장(Scaling)
- 여러 개의 스위칭 "평면(plane)"을 병렬로 사용하여 확장할 수 있다.
- 병렬 처리를 통해 스위칭 속도와 성능을 향상시킬 수 있다.
- Cisco CRS 라우터
- 기본 유닛: 8개의 스위칭 평면을 사용한다.
- 각 평면은 3단계 상호 연결 네트워크로 구성된다.
- 수백 Tbps에 달하는 스위칭 용량을 제공한다.
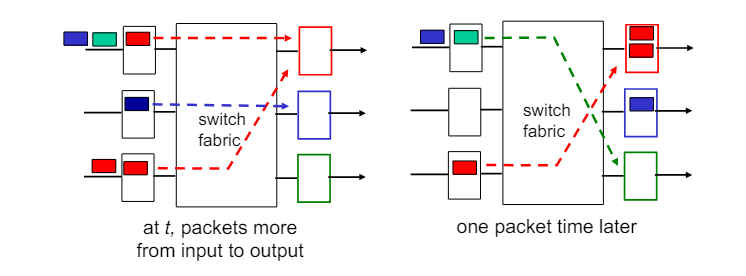
Input port queuing
input port에서 발생하는 queuing 현상과 Head-of-Line(HOL) 블로킹에 대해 설명한다.
- 스위치 패브릭 속도와 입력 포트:
- 스위치 패브릭의 속도가 입력 포트의 총합보다 느리면 입력 큐에서 큐잉이 발생할 수 있다.
- 입력 버퍼 오버플로우로 인해 큐잉 지연과 데이터그램 손실이 발생할 수 있다.
- Head of Line(HOL)블로킹
- queue의 앞 부분에 있는 데이터그램이 다른 데이터그램의 전진을 방해하는 현상이다.

================================================================
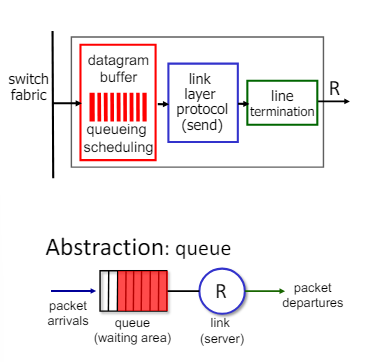
Output port queuing
버퍼링(Buffering)
- 스위치 패브릭에서 데이터그램이 링크 전송 속도보다 빠르게 도착할 때 버퍼링이 필요하다.
- 드롭 정책(Drop Policy)
- 버퍼가 가득 차면 어떤 데이터그램을 버릴지 결정하는 정책이다
- 혼잡이나 버퍼 부족으로 인해 데이터그램이 손실될 수 있다.
스케줄링 규칙(Scheduling Discipline)
- 큐에 있는 데이터그램 중 어떤 것을 전송할지 선택하는 규칙이다.
- 우선순위 스케줄링(Priority Scheduling)
- 누가 최고의 성능을 받을지 결정하는 과정이다.
- 네트워크 중립성 문제와 관련될 수 있다.
- 누가 최고의 성능을 받을지 결정하는 과정이다.
- 우선순위 스케줄링(Priority Scheduling)
- 큐에 있는 데이터그램 중 어떤 것을 전송할지 선택하는 규칙이다.
================================================================
- 버퍼링은 arrival rate가 output line speed를 넘을 때 발생한다.
- queueing(delay) and loss는 output buffer의 overflow 때문이다.
Buffer Management
버퍼 관리(Buffer Management)
- Drop
- 버퍼가 가득 찼을 때 어떤 패킷을 추가하고, 어떤 패킷을 드롭할지 결정하는 과정
- 테일 드롭(Tail Drop): 도착한 패킷을 드롭한다.
- 우선 순위(Priority): 우선순위에 따라 패킷을 드롭하거나 제거한다.
- Marking
- 혼잡을 신호하기 위해 어떤 패킷을 마크할지 결정한다.(ECN, RED)
- Drop
큐잉과 스케줄링(Queuing and Scheduling)
- 큐잉은 패킷이 도착하여 대기하는 영역을 관리한다.
- 스케줄링은 대기 중인 패킷 중 어떤 것을 먼저 전송할지 결정한다.
Packet Scheduling:FCFS
*packet scheduling: *
- FCFS
- Priority
- round robin
- Weighted Fair Queueing: 각 큐에 가중치를 부여하여 공정하게 전송

FCFS: 패킷이 도착한 순서대로 출력 포트로 전송된다.
Scheduling Policies: priority
우선순위 스케줄링
- 도착한 트래픽을 분류하고 클래스별로 큐에 저장
- 패킷 헤더의 다양한 필드를 분류에 사용할 수 있다.
- 가장 높은 우선순위 큐에 있는 패킷부터 전송
- 우선순위 클래스 내에서는 FCFS 방식으로 처리

Scheduling policies: round robin
라운드 로빈 스케줄링
- 도착한 트래픽을 분류하고 클래스별로 큐에 저장
- 패킷 헤더의 다양한 필드를 분류에 사용할 수 있다.
- 서버는 주기적으로 각 클래스 큐에 스캔하며, 각 클래스에서 하나의 패킷을 차례대로 전송한다.
- 모든 클래스 큐가 동일하게 처리되므로 공정한 스케줄링이 가능하다.
트래픽 분류(Traffic Classification)
- 도착한 트래픽은 분류되어 각 클래스 큐에 저장된다.
- e.g. 높은 우선순위 트래픽, 보통 우선순위 트래픽, 낮은 우선순위 트래픽
주기적 스캔 및 전송(Cyclic Scanning and Transmission)
- 서버는 주기적으로 각 클래스 큐를 스캔한다.
- 각 클래스에서 하나의 패킷을 선택하여 전송한다.
- 각 클래스 큐가 돌아가며 패킷을 전송하게 된다.

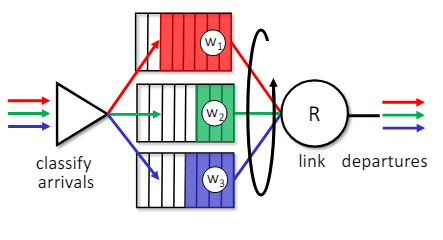
Scheduling polices: weighted fair queueing
Weighted Fair Queuing(WFQ)
- 일반화된 라운드 로빈
- 가중치 부여(Weighting)
- 각 클래스 i는 가중치 wi를 가지며, 각 주기에 가중치에 비례한 양의 서비스를 받는다.
- 각 클래스가 받은 서비스의 비율은 다음과 같다.
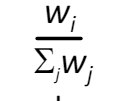
- minimum bandwidth 보장(per-traffic-class)
Sidebar: Network Neutrality
네트워크 중립성이란 무엇인가?
기술적 관점
- ISP(인터넷 서비스 제공자)가 자원을 어떻게 공유하고 할당해야 하는지에 관한 것
- 패킷 스케줄링, 버퍼 관리 등이 이러한 자원 할당을 위한 메커니즘이다.
사회적, 경제적 원칙
- 자유로운 표현 보호
- 혁신과 경쟁 촉진
법적 규칙과 정책의 시행
Network Layer: Internet
네트워크 계층 기능
- 경로 선택 알고리즘(Path-Selection-Algorithms)
- 라우팅 프로토콜(OSPF, BGP) 및 SDN 컨트롤러에서 구현된다.
- 경로 선택 알고리즘은 데이터그램이 목적지까지 가는 최적의 경로를 결정한다.
- IP 프로토콜(IP Protocol)
- 데이터그램 형식(Datagram Format)
- 데이터그램의 구조를 정의
- 주소 지정(Addressing)
- 데이터그램이 올바른 목적지에 도달하도록 주소를 지정한다.
- 패킷 처리 규칙(Packet Handling Coventions)
- 데이터그램이 네트워크를 통해 올바르게 전송되도록 처리 규칙을 정의한다.
- 데이터그램 형식(Datagram Format)
- ICMP 프로토콜(ICMP Protocol)
- 오류 보고(Error Reporting)
- 데이터그램 전송 중 발생하는 오류를 보고
- 라우터 신호(Router Signaling)
- 라우터 간 신호 전달을 관리한다.
- 오류 보고(Error Reporting)
- 포워딩 테이블(Forwarding Table)
- 데이터그램을 다음 목적지로 전달하기 위한 경로 정보를 저장한다.
IP Datagram foramt

IP addressing: introduction
IP addressing:
- 32비트 식별자
- 각 호스트나 라우터 인터페이스에 할당된다
- e.g. 223.1.1.1
인터페이스
- 호스트/라우터와 물리적 링크 간의 연결을 의미한다.
- 라우터는 보통 여러 개의 인터페이스를 가진다.
- 호스트는 보통 하나 또는 두 개의 인터페이스를 가진다.(e.g. 유선 이더넷, 무선 802.11)

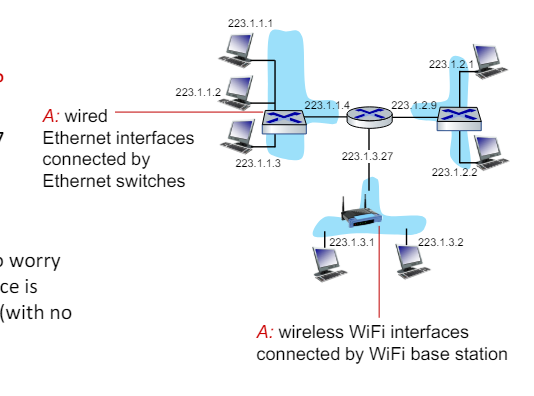
Subnets
- 서브넷이란?
- 라우터를 거치지 않고 물리적을 서로 도달할 수 있는 장치 인터페이스들의 집합이다.
- e.g. 같은 네트워크 스위치나 WiFi 기지국에 연결된 장치들
- IP주소의 구조(IP Addresses Have Structure)
- 서브넷 부분(Subnet Part)
- 같은 서브넷에 속한 장치들은 공통된 상위 비트를 가진다.
- 호스트 부준(Host Part)
- 나머지 하위 비트들은 호스트를 식별하는 데 사용된다.
- 서브넷 부분(Subnet Part)

- 서브넷의 정의 방법
- 각 인터페이스를 호스트나 라우터에서 분리하여 고립된 네트워크 "섬"을 만든다.
- 이렇게 고립된 네트워크를 "서브넷"이라고 부른다.
서브넷 구성
서브넷 마스트(Subnet Mask)
'/24'는 상위 24비트가 서브넷 부분임을 나타낸다.

서브넷 예시
- 223.1.1.0/24: IP 주소 범위는 223.1.1.0에서 223.1.1.255까지.
- 223.1.2.0/24: IP 주소 범위는 223.1.2.0에서 223.1.2.255까지.
- 223.1.3.0/24: IP 주소 범위는 223.1.3.0에서 223.1.3.255까지.

- 서브넷의 위치
- 네트워크 내에서 여러 서브넷이 존재한다.
- 각 서브넷은 라우터와 호스트를 포함하며, 특정 IP 주소 범위를 가진다.
- /24 서브넷 주소(What are the /24 Subnet Addresses?)
- 각 서브넷의 주소는 /24 서브넷 마스크를 사용하여 정의된다.
- /24 서브넷 마스크는 상위 24비트가 서브넷 부분임을 나타낸다.

IP addressing: CIDR
- CIDR 정의
- CIDR은 Classless InterDomain Routing의 약자로, "cider"로 발음된다.
- 주소의 서브넷 부분의 길이를 임의로 지정할 수 있다.
- 주소 형식(Address Foramt)
- 주소 형식은 a.b.c.d/x 형태로, 여기서 'x'는 서브넷 부분의 비트 수를 나타낸다.
- e.g. 200.23.16.0/23
- 서브넷 부분과 호스트 부분(Subnet Part and Host Part)
- 주소의 앞부분은 서브넷 부분이고, 뒷부분은 호스트 부분이다.
- e.g. 200.23.16.0/23의 경우, 앞의 23비트가 서브넷, 나머지 비트는 호스트부분이다.
IP Addresses:How to Get One?
- 두 가지 질문(Two Questions)
- Q1. 호스트가 자신의 네트워크 내에서 IP주소를 어떻게 얻는가?(호스트 주소 부분)
- Q2. 네트워크가 자체적으로 IP 주소를 어떻게 얻는가?(네트워크 주소 부분)
- 호스트가 IP 주소를 얻는 방법(How Does a Host Get IP Address)
- 시스템 관리자에 의해 고정 설정(Hard-Coded by Sysadmin)
- 시스템 관리자가 구성 파일(e.g. UNIX의 /etc/rc.config)에서 IP 주소를 고정 설정한다.
- DHCP(Dynamic Host Configuration Protocol)
- DHCP 서버로 부터 동적으로 IP 주소를 얻는다
- plug and play 방식을 자동 설정
- 시스템 관리자에 의해 고정 설정(Hard-Coded by Sysadmin)
DHCP: Dynamic Host Configuration Protocol
- 목표(Goal)
- 호스트가 네트워크에 연결될 때 네트워크 서버로부터 동적으로 IP 주소를 받는다.
- 사용 중인 주소의 임대를 갱신할 수 있다.
- 주소의 재사용을 허용한다.(연결된 동안에는 주소를 유지)
- 네트워크에 가입하고 탈퇴하는 모바일 사용자를 지원
- DHCP 개요
- DHCP discover 메시지
- 호스트가 네트워크에 가입할 때 브로드캐스트로 DHCP discover 메시지를 보낸다.(선택사항)
- DHCP offe 메시지
- DHCP 서버가 IP 주소를 제안하는 DHCP offer 메시지로 응답한다.(선택사항)
- DHCP request 메시지
- 호스트가 DHCP 서버에 IP 주소 요청 메시지를 보낸다.
- DHCP ack 메시지
- DHCP 서버가 IP 주소를 할당하는 DHCP ack 메시지를 보낸다.
- DHCP discover 메시지
DHCP: Client-Server Scenario
- DHCP 서버의 위치(DHCP Server Location)
- DHCP 서버는 보통 라우터와 함께 위치한다.
- 라우터에 위치한 모든 서브넷에 IP 주소를 할당한다.
- DHCP 클라이언트의 동작(DHCP Client Operation)
- 네트워크에 새로 연결된 DHCP 클라이언트가 IP 주소를 필요로 한다.
- DHCP 클라이언트는 네트워크에 연결될 때 DHCP 서버와 상호작용하여 IP 주소를 얻는다.

DHCP client-server scenario
- DHCP discover(탐색)
- 클라이언트: DHCP 서버가 있나요? 라는 메시지를 브로드 캐스트한다.
- 이는 네트워크에 DHCP 서버가 있는지 탐색하는 단계이다.
- DHCP offer(제공)
- DHCP 서버: 나는 "DHCP 서버입니다. 사용할 수 있는 IP 주소가 여기에 있습니다." 라는 메시지를 브로드캐스트한다.
- DHCP 서버는 사용 가능한 IP 주소를 클라이언트에게 제안한다.
- DHCP reqeust(요청)
- 클라이언트: "알겠습니다. 이 IP 주소를 사용하고 싶습니다!" 라는 메시지를 브로드캐스트한다.
- 클라이언트는 제안된 IP 주소를 사용하겠다고 요청한다.
- DHCP ACK(승인)
- DHCP 서버: "알겠습니다. 이 IP 주소를 할당했습니다." 라는 메시지를 브로드캐스트한다.
- DHCP 서버는 클라이언트에게 IP 주소를 할당하고 이를 확인한다.

DHCP: more than IP addresses
DHCP가 반환하는 추가 정보
- 클라이언트를 위한 첫 홉 라우터의 주소(Address of First-Hop Router for Client)
- 클라이언트가 네트워크 상에서 통신을 시작할 때 사용하는 첫 번째 라우터의 IP 주소
- DNS 서버의 이름과 IP 주소(Name and IP Address of DNS Server)
- 클라이언트가 도메인 이름을 IP주소로 변환할 때 사용하는 DNS 서버의 정보
- 네트워크 마스크(Network Mask)
- 네트워크와 호스트 부분을 구분하는 서브넷 마스크
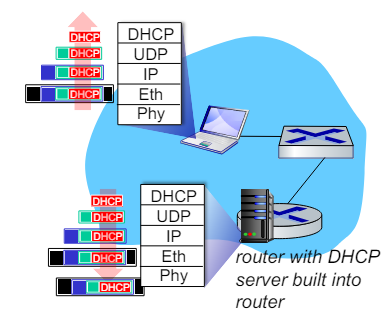
DHCP: example
DHCP가 실제로 어떻게 작동하는가?
- 노트북 연결(Connecting Laptop)
- 노트북을 네트워크에 연결하면 DHCP를 사용하여 IP주소, 첫 홉 라우터의 주소, DNS 서버의 주소를 얻는다.
- DHCP 요청 메시지(DHCP REQUEST Message)
- DHCP REQUEST 메시지는 UDP에 캡슐화되고, 다시 IP에 캡슐화되고, 최종적으로 이더넷에 캡슐화된다.
- 이는 메시지가 전송될 때 여러 프로토콜 계층을 통해 포장되는 과정을 나타내다.
- 이더넷 프레임 브로드캐스트(Ethernet Frame Broadcast)
- 이더넷 프레임은 네트워크 상에서 브로드캐스트된다. 목적지 주소는 'FFFFFFFFFFFF'(모든 노드에게 전송됨)이다.
- DHCP 서버가 실행 중인 라우터에게 이 프레임을 수신한다.
- 프레임 디멀티플렉싱(Frame Demultiplexing)
- 이더넷 프레임이 IP로 디멀티플랙싱되고, IP는 UDP로 디멀티플랙싱 된다.
- 최종적으로 UDP는 DHCP로 디멀티플랙싱된다.
- 이는 각 프로토콜 계층이 데이터 단위로 상위 계층으로 전달하는 과정을 설명한다.

- DHCP 서버 응답(DHCP Server Reply)
- DHCP 서버는 클라이언트의 IP 주소, 첫 홉 라우터의 IP 주소, DNS 서버의 이름과 IP 주소를 포함한 DHCP ACK 메시지를 작성한다.
- 이 메시지는 클라이언트에게 전송된다.
- DHCP 서버 응답 캡슐화(Encapsulated DHCP Server Reply)
- DHCP ACK 메시지는 여러 프로토콜 계층을 통해 캡슐화되어 클라이언트에게 전달된다.
- 클라이언트에서 해당 메시지를 수신하고 각 계층을 통해 디멀티플렉싱하여 DHCP 메시지를 처리한다.
- 클라이언트 정보 획득(Client Information Acquisition)
- 클라이언트는 이제 자신의 IP 주소, DNS 서버 이름과 IP 주소, 첫 홉 라우터의 IP 주소를 알게 된다.
IP addresses: how to get one
Q. 네트워크가 IP 주소의 서브넷 부분을 어떻게 얻는가?
A. 네트워크는 ISP가 할당한 주소 공간의 일부를 받는다

Hierarchinal addressing: route aggregation
계층적 주소 지정: 경로 집계
- 계층적 주소 지정
- 계층적 주소 지정은 라우팅 정보를 효율적으로 광고하는 것을 가능케한다.
- 이는 여러 개의 작은 네트워크 주소를 하나의 큰 주소로 집계하여 라우팅 테이블 크기를 줄이는 데 도움을 준다.
===================59,60,61,62 페이지 생략======================================
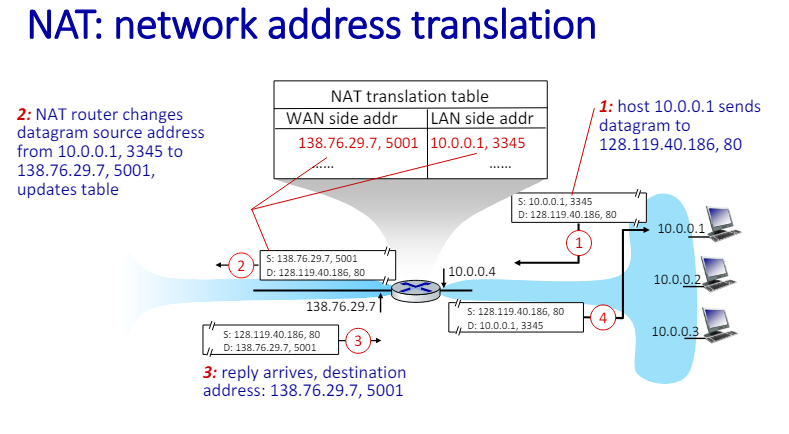
NAT:network address translation

네트워크 주소 변환(NAT)의 개념과 작동 방식을 설명함
- NAT의 개념
- 로컬 네트워크의 모든 장치는 "사설" IP 주소 공간(10/8, 172.16/12, 192.168/16 프리 픽스)를 사용한다.
- 이런 사설 IP 주소는 로컬 네트워크에서만 사용할 수 있다.
- NAT는 로컬 네트워크의 모든 장치가 외부 세계에 대해 단 하나의 IPv4 주소를 공유하도록 한다.
- 예를 들어, 가정 네트워크 주소가 10.0.0.0/24 인 경우, 모든 장치는 외부 세계에 대해 138,76,29,7의 단일 NAT IP 주소를 사용하게 된다.
- 로컬 네트워크와 외부 인터넷
- 로컬 네트워크 내의 장치들은 로컬 IP 주소를 사용한다. e.g. 10.0.0.1, 10.0.0.2, 10.0.0.3
- 이 장치들이 인터넷과 통신할 때, NAT 라우터는 이들의 로컬 IP 주소를 공인 IP 주소(138.76.29.7)
- 데이터그램 전송
- 로컬 네트워크를 떠나는 모든 데이터그램은 동일한 NAT IP 주소(138.76.29.7)를 가지지만, 각 데이터그램은 다른 소스 포트 번호를 가진다.
- 로컬 네트워크 내에서 송수신되는 데이터그램은 여전히 로컬 주소(10.0.0.0/24)를 사용한다.
- NAT의 장점
- 단 하나의 IP 주소: 모든 장치에 대해 공급자 ISP로부터 단 하나의 공인 IP 주소만 필요한다.
- 내부 주소 변경: 외부 세계에 알릴 필요 없이 로컬 네트워크 내 호스트의 주소를 변경할 수 있다.
- ISP 변경 용이: 로컬 네트워크 내 장치들의 주소를 변경하지 않고도 ISP를 변경할 수 있다.
- 보안: 로컬 네트워크 내부의 장치는 외부 세계에서 직접적으로 주소가 지정되거나 보이지 않는다.
NAT: network address translation
NAT 라우터의 구현 방식
- NAT 라우터의 역할
- NAT 라우터는 투명하게 다음과 같은 작업을 수행해야 한다.
- 출발 데이터그램(outgoing datagrams)
- 모든 출발 데이터그램의 소스 IP 주소와 포트 번호를 (NAT IP 주소, 새로운 포트 번호) 로 대체
- 원격 클라이언트/서버는 (NAT IP 주소, 새로운 포트 번호)를 목적지 주소로 사용하여 응답한다.
- NAT translation table에 기억
- 모든 (소스 IP 주소, 포트 번호) 와 (NAT IP 주소, 새로운 포트 번호) 의 번역 쌍을 NAT 번역 테이블에 저장한다.
- 도착 데이터그램(incoming datagrams)
- (NAT IP address, new port #)을 (source IP address, port #)로 replace
- 모든 도착 데이터그램의 목적지 필드를 NAT 테이블에 저장된 대응하는 (소스 IP 주소, 포트 번호)로 대체한다.
NAT: network address translation
논란과 현황
논란
- 라우터 처리 계층 문제
- 라우터는 원래 3계층(네트워크 계층)까지만 처리해야 한다고 여겨진다.
- 그러나 NAT는 포트 번호를 변경하는 등 4계층(전송 계층)까지 처리한다.
- 주소 부족 문제
- IPv6를 통해 주소 부족 문제를 해결해야 한다고 주장
- IPv6는 더 많은 IP 주소를 제공하여 NAT 없이도 충분히 네트워크를 구성할 수 있다.
- 종단 간 논쟁 위반
- NAT는 네트워크 계층 장치가 포트 번호를 조작하여 종단 간 통신의 투명성을 위반한다.
- 이는 종단 간 논쟁(end-to-end argument)을 위반하는 행위로 여겨진다.
- NAT traversal 문제
- 클라이언트가 NAT 뒤에 있는 서버와 연결하고자 할 때 NAT traversal 문제가 발생한다.
- 이는 NAT가 외부에서 들어오는 트래픽을 적절히 전달하기 어렵게 만든다.
허나
NAT는 현재 널리 사용되고 있다.
- 가정용 네트워크와 기관 네트워크에서 광범위하게 사용된다.
- 4G/5G 셀룰러 네트워크에서도 NAT가 사용된다.
IPv6: motivation
등장배경:
- IPv4 주소 공간 고갈: 32비트의 IPv4 주소 공간이 완전히 할당될 것이 예상되었다.
- IPv4 주소 공간은 약 43억 개의 고유 주소를 제공한다.
- 인터넷 사용자와 장치의 폭발적인 증가로 인해 IPv4 주소가 부족해졌다.
- 처리 및 포워딩 속도 향상: 40 바이트 고정 길이 헤더를 사용하여 처리 속도를 높였다.
- 흐름에 대한 네트워크 계층 처리 기능: 다양한 네트워크 계층에서 흐름(flow)을 다르게 처리할 수 있는 기능을 제공한다.
IPv6 datagram format
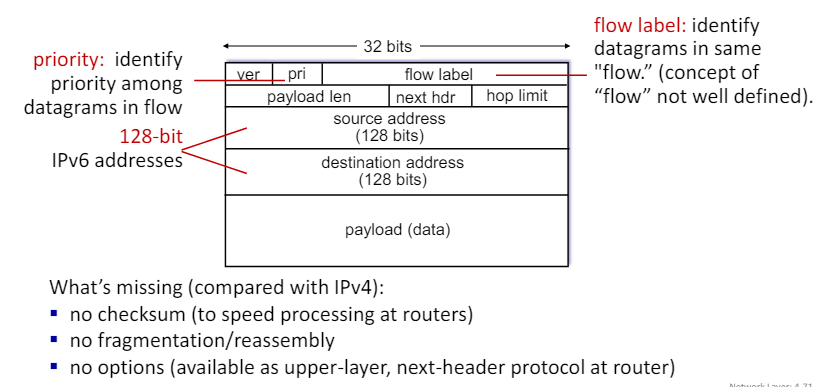
IPv4와 비교에서 없는 것
- checksum이 없다.: 라우터에서 처리 속도를 높이기 위해 체크섬 필드가 제거되었다.
- no fragmentation/reassemply: IPv6는 단편화와 재조립을 지원하지 않는다. 대신, 상위 계층에서 이 기능을 처리한다.
- no option: IPv4에서는 다양한 옵션을 제공했지만, IPv6에서는 이러한 옵션이 제거되고 대신 상위 계층이나 다음 헤더 프로토콜에서 제공된다.
Transition from IPv4 to IPv6
IPv4에서 IPv6로의 전환은 네트워크 인프라 전반에 걸쳐 일괄적으로 이루어질 수 없기에 점진적인 전환 방법이 필요하다.
- 주요 내용
- 모든 라우터의 동시 업그레이드 불가: 모든 라우터를 동시에 업그레이드할 수 없으며, 이를 위한 "flag day" 같은 날을 정할 수도 없다.
- 혼합 운영: 네트워크 IPv4와 IPv6 라우터가 혼재된 환경에서 운영될 수 있다.
- 터널링(Tunneling)
- 터널링 정의: 터널링은 IPv6 데이터그램을 IPv4 데이터그램의 페이로드로 운반하는 방법이다. 이는 "패킷 안의 패킷" 방식으로 작동한다.
- 운영 방식: IPv4 헤더는 소스 및 목적지 주소를 포함하고, 이 IPv4 헤더 안에 IPv6 데어터그램 전체가 포함된다. IPv6 데이터그램 내부에는 다시 IPv6 헤더 필드와 UDP/TCP 페이로드가 포함된다.
- 터널링의 활용: 터널링은 4G/5G 네트워크와 같은 다른 컨텍스트에서도 광범위하게 사용된다.
- 도식 설명
- IPv4 헤더 필드: 소스 주소와 목적지 주소가 포함된 IPv4 헤더가 데이터그램의 맨 앞부분을 차지한다.
- IPv6 데이터그램: IPv4 헤더 뒤에는 IPv6 데이터그램이 포함되며, 여기에는 IPv6 헤더 필드와 UDP/TCP 페이로드가 포함된다.
- 페이로드: 최종적으로 IPv4 페이로드로 감싸진 전체 패킷이 전송된다.

Generalized forwarding: match plus action
주요 내용
- 포워딩 테이블: 각 라우터는 포워딩 테이블(또는 플로우 테이블)을 포함한다.
- "매치 플러스 액션" 추상화: 도착하는 패킷의 비트를 매치하고, 특정 동작을 취한다.
- 목적지 기반 포워딩: 목적지 IP 주소에 기반하여 포워딩을 수행한다.
- 일반화된 포워딩: 여러헤더 필드가 액션을 결정할 수 있으며, 다양한 액션이 가능하다.
포워딩 테이블(Forwarding Table)
- 포워딩 테이블 역할: 도착하는 패킷의 특정 비트를 확인하고, 그에 맞는 액션을 결정한다.
- 일반화된 포워딩: 단순히 목적지 IP 주소뿐만 아니라, 여러 헤더 필드도 고려할 수 있다.
- 가능한 액션들
- 드롭(drop): 패킷을 폐기합니다.
- 복사(copy): 패킷을 복사한다.
- 수정(modify): 패킷의 내용을 수정한다.
- 로그(log): 패킷을 로그에 기록

Flow Table abstraction
- 플로우(Flow): 헤더 필드 값에 의해 정의된다.(링크 계층, 네트워크 계층, 전송 계층의 필드 포함)
일반화된 포워딩(Generalized Forwarding): 단순한 패킷 처리 규칙을 포함한다.
- 매치(Match) : 패킷 헤더 필드에서 패턴 값을 매칭한다.
- 액션(Action): 매치된 패킷에 대해 다음과 같은 동작을 수행할 수 있다.
- drop: 패킷을 폐기함
- forward: 패킷을 전달함
- modify: 패킷을 수정함
- send to controller: 매치된 패킷을 컨트롤러로 보낸다.
- Priority: 겹치는 패턴을 구별한다.
- Counters: 바이트 수와 패킷 수를 세어준다.
그림
- Flow Table: 라우터의 매치 + 액션 규칙을 정의
- match: 패킷의 헤더 필드를 매칭
- 액션: 매치된 패킷에 대해 정의된 액션을 수행
- src = ..., dest=3.4..: forward(2번 포트로 전달)
- src=1.2.., dest=...: drop(패킷 폐기)
- src=10.1.2.3, dest=...: controller로 전송
OpenFlow: 플로우 테이블 항목
주요 내용
- Match(매치): 패킷의 헤더 필드 값을 기준으로 매치
- Action(액션): 매치된 패킷에 대해 수행할 동작을 정의
- 패킷을 특정 포트로 전달
- 패킷 폐기
- 헤더 필드 수정
- 캡슐화하여 컨트롤러로 전달
- 패킷을 특정 포트로 전달
- Stats(통계): 패킷과 바이트 카운터를 포함

OpenFlow: examples


OpenFlow abstraction
- match + action
- 이 추상화는 다양한 종류의 네트워크 장치를 통합하는 개념이다. 모든 네트워크 장치는 특정 조건을 매칭하고, 그에 따른 행동을 수행한다.
- Router(라우터)
- match(매칭)
- 가장 긴 목적지 IP 접두사(longest destination IP prefix)를 매칭한다. 즉, 목적지 IP 주소가 특정 범위에 속하는지를 확인한다.
- action(행동)
- 해당 링크로 패킷을 전달한다(forward out a link)
- match(매칭)
- Switch(스위치)
- match(매칭)
- 목적지 MAC 주소(destination MAC address)를 매칭한다. 즉, 이더넷 프레임의 목적지 MAC 주소를 확인한다.
- action(행동)
- 패킷을 전달하거나 (forward) 모든 포트로 전송(flood)한다.
- match(매칭)
- Firewall(방화벽)
- match(매칭)
- IP 주소와 TCP/UDP 포트 번호를 매칭한다. 즉, 특정 IP 주소와 포트 번호로 들어오는 패킷을 확인한다.
- action(행동)
- 패킷을 허용하거나 (permit) 차단한다. (deny)
- IP 주소와 TCP/UDP 포트 번호를 매칭한다. 즉, 특정 IP 주소와 포트 번호로 들어오는 패킷을 확인한다.
- match(매칭)
- NAT(Network Address Translation, 네트워크 주소 변환)
- match(매칭)
- IP 주소와 포트를 매칭한다. 즉, 내부 네트워크의 특정 IP 주소와 포트를 확인한다.
- action(행동)
- 주소와 포트를 재작성 (rewrite)한다. 즉, 내부 네트워크 주소를 외부 네트워크 주소로 변환한다.
- match(매칭)
OpenFlow example

Generalized forwarding : summary
match plus action: Abstraction
- 개념: 패킷 헤더의 비트를 다양한 계층에서 일치시키고 해당하는 동작을 수행하는 추상화
- 매칭: 링크, 네트워크, 전송 계층의 여러 필드에 대해 매칭한다.
- 로컬 액션: 패킷을 드롭, 포워드, 수정, 컨트롤러로 보낼 수 있다.
- 네트워크 전반의 동작: 네트워크 전체의 동작을 "프로그래밍"할 수 있다.
network programmability
- 간단한 형태: 패킷당 "처리"를 프로그래밍할 수 있다.
- 역사적 배경: 활성 네트워킹에서 시작되었다.
- 오늘날: 더 일반화된 프로그래밍을 의미하며, P4와 같은 도구를 사용한다.
Middleboxes
- Middlebox; 일반적인 IP 라우터의 표준 기능 외에 다른 기능을 수행하는 중간 장치이다. 이러한 장치는 소스 호스트와 목적지 호스트 사이의 데이터 경로에 위치한다
Middleboxes everywhere!
주요 middlebox의 종류와 용도
- NAT(Network Address Translation)
- 용도: 여러 장치들이 하나의 공인 IP 주소를 공유하도록 함
- 사용처: 가정, 셀룰러 네트워크, 기관 네트워크
- Application-specific Middleboxes
- 용도: 특정 어플리케이션의 성능 및 보안을 위해 설계된 중간 장치
- 사용처: 서비스 제공자. 기관 네트워크, CDN(컨텐츠 전송 네트워크)
- Firewalls, IDS(Intrusion Detection Systems)
- 용도: 네트워크 보안을 강화하고 침입을 탐지 및 차단
- 사용처: 기업, 기관, 서비스 제공자, ISP(인터넷 서비스 제공자)
- Load Balancers
- 용도: 트래픽을 여러 서버에 분산하여 부하를 균등하게 분배
- 사용처: 기업 네트워크, 서비스 제공자, 데이터 센터, 모바일 네트워크
- Caches
- 용도: 자주 사용하는 데이터를 로컬에 저장하여 접근 속도를 향상
- 사용처: 서비스 제공자, 모바일 네트워크, CDN

Middleboxes
초기 Middlebox
- 초기 형태: 초기 Middlebox는 독점적인 하드웨어 솔루션으로, 폐쇄된 시스템을 사용했다.
Whitebox 하드웨어로의 이동
- Whitebox 하드웨어: 오픈 API를 구현한 범용 하드웨어로의 전환이 진행되고 있다.
- 독점 하드웨어 탈피: 기존의 독점적인 하드웨어 솔루션에서 벗어나고 있다.
- 프로그래밍 가능한 로컬 액션: 'match+action' 메커니즘을 통해 로컬에서 프로그래밍 가능한 작업을 수행할 수 있다.
- 소프트웨어 혁신: 소프트웨어에서의 혁신과 차별화로 나아가고 있다.
SDN(Software Defined Networking)
- 중앙 집중식 관리: 논리적으로 중앙 집중식 제어 및 구성 관리를 제공하며, 종종 사설 또는 공용 클라우드에서 수행된다.
NFV(Network Functions Virtualization)
- 프로그래머블 서비스: Whitebox 네트워킹, 계산 및 저장소를 통해 프로그래밍 가능한 서비스를 제공한다
The IP hourglass
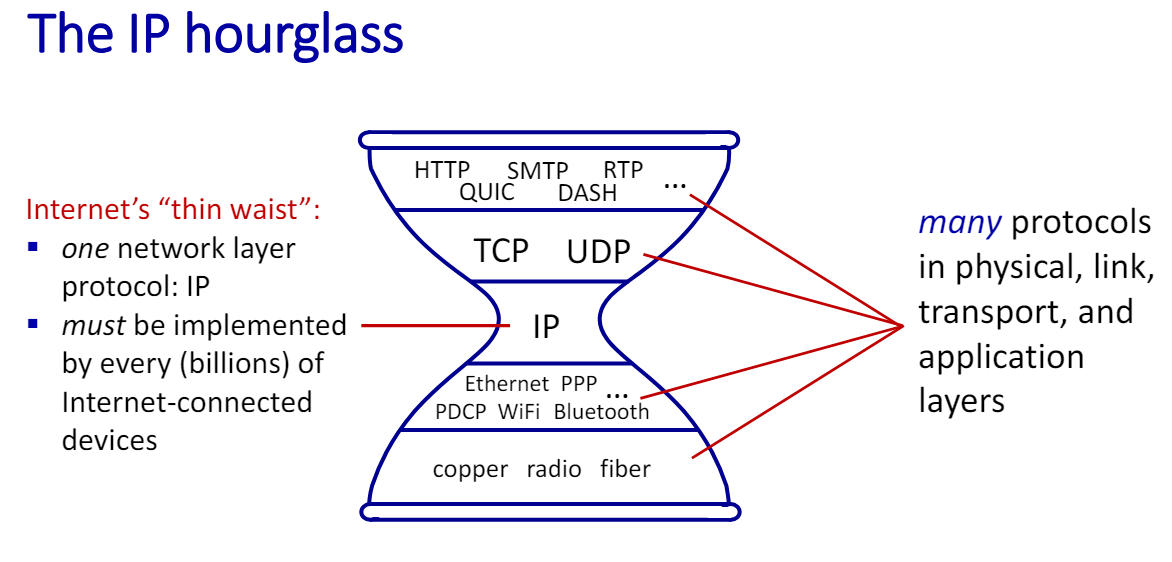
하나의 네트워크 계층 프로토콜(IP)
- 인터넷에서 사용되는 유일한 네트워크 계층 프로토콜은 IP(Internet Protocol)이다.
- IP는 전 세계의 수십억 개의 인터넷 연결 장치에 의해 구현되어야 한다.

인터넷의 "love handles"
- 인터넷이 시간이 지나면서 네트워크 내부에서 동작하는 다양한 중간 장치(middleboxes)가 등장했다.