SOP(Same Origin Policy)
다른 출처의 리소스를 사용하는 것을 제한을 거는 보안 방식
SOP를 사용해야하는 예시
- 어떤 유저가 FaceBook에 로그인을 하고 토큰을 받아 로그인 과정을 완료했다.
- 유저는 로그인한 상태로 메일(http://hacker.com)을 받았다.
- 메일은 페이스북에 악의적으로 실행되는 script 코드를 작성하였다.
- 이때 페이스북에 유저의 토큰을 가지고 해커의 출처(origin) 을 통해 글을 작성하려고 한다.
- 이때 SOP 정책에 의해 요청을 확인하고 다른 출처(origin)을 가지게 되므로 페이스북에서 자신의 출처와 다른 출처를 가지므로 SOP 정책에 의해 해당 요청을 거부하게 된다.
CORS란?
Cross-Origin Resource Sharing으로서 다른 출처(origin)의 자원을 공유할 수 있게 허용하는 정책을 뜻한다. 여기서 Origin은 protocol + host + port를 합한 것으로 이 세가지가 동일하면 같은 origin이라고 판단한다. 예를 들어 http://123.456.789.123:3000과 http://123.456.789.123:8001은 다른 Origin이다.
과거 front와 back이 분리되어 있지 않던 시절에는 front와 back이 같은 Origin에 있었다. 하지만 둘이 분리되면서 각기 다른 서버에 존재하기 시작하면서 문제가 발생하기 시작했다. 별도로 존재하는 frontend server와 backend server로 요청(request)이 이뤄져야 하는 상황이 되었다. 동시에 어떤 곳에서 bacnend server는 request가 들어왔을 때 신뢰할 수 있는 것인지 알 수 없게 됬다. 따라서, backend server 쪽에서 어떤 Origin에서 request가 들어왔을 때, 받아줄 것인지 허용 Origin에 대해서 정의해줄 필요가 생겼다.
backend: "나는 이 Origin에서 이뤄지는 요청만 처리해줄거야. 다른 Origin은 믿을 수 없어. 해커가 날 공격할 수도 있잖아?"
그런데 일단 frontend에서 backend 쪽으로 요청을 보내기 전 미리 preflight request를 보낸다. 그러면 backend는 이를 통해 허용된 origin인지를 판단하고 응답한다.
preflight request란?
preflight request는 실제 request 전에 browser에서 보내는 작은 request이다. 지금 request을 보내는 frontend가 backend server에서 허용한 Origin이 맞는지, 그리고 해당 endpoint에서 어떤 HTTP method들을 허용하는지 등을 확인한다. 만약 허용되는 Origin이고 요청하는 메소드도 허용되는 것이라면 실제 request을 할 수 있게 해준다. 그렇지 않다면, 실제 request를 보내기도 전에 보내지 못하게 막는 것이다.

만일 preflight request가 이루어질려면 server에서 OPTIONS method를 허용해줘야 한다. preflight request는 OPTIONS method에 의해 만들어지기 때문이다.
CORS 작동 방식
위에서 언급한 preflight reqeust는 CORS의 작동 방식 중 하나이다. CORS 작동 방식은 아래 3가지와 같은 것들이 있다.
1. preflight request
preflight는 CORS 상황에서 보안을 확인하기 위해 브라우저가 제공하는 기능이다.
preflight는 미리 통신을 함으로써 문제가 있는 요청에 대해 일부러 ERROR를 발생시킨다.
요새는 크롬 개발자도구에서 preflight를 표기해서 어디서 preflight가 발생했는지 확인하기 쉬워졌다.
request를 바로 보내지 않고 preflight request를 보내서 허용되는 method가 무엇인지, 허용되는 Origin인지 등을 먼저 확인한다. 브 라우저와 서버는 다음과 같은 방식으로 통신한다.
- 브라우저는 서버로 HTTP OPTIONS method로 preflight request를 보낸다.
- Origin header에는 자신의 출처를 넣는다.
- Access-Control-Request-Method header에 실제 request에 사용할 method를 설정한다.
- Access-Control-Request-Headers header에 실제 request에 사용할 header들을 설정한다.
- server는 이 preflight request에 대한 response으로 허용되는 것들에 대한 정보를 header에 담아서 browser로 보낸다.
- Access-Control-Allow-Origin header에 허용되는 Origin들을 알려준다.
- Access-Control-Allow-Methods header에 허용되는 Method들을 알려준다.
- Access-Control-Allow-Headers header에 허용되는 header들을 알려준다.
- Access-Control-Max-Age header에 해당 preflight request가 브라우저에 캐시 될 수 있는 시간을 초 단위로 알려준다.
- Access-Control-Max-Age header: 이 preflight 요청에 대한 결과를 브라우저가 얼마나 오랫동안 cache 할 수 있는지를 지정한다.
만일 지정된 시간 동안에는 동일한 조건의 요청이 있을 때, preflight request를 다시 보내지 않고, cache된 정보를 사용하여 본 request를 바로 수행할 수 있다. 이는 네트워크 트래픽을 줄이고, 성능을 향상시키는 데 도움이 된다.
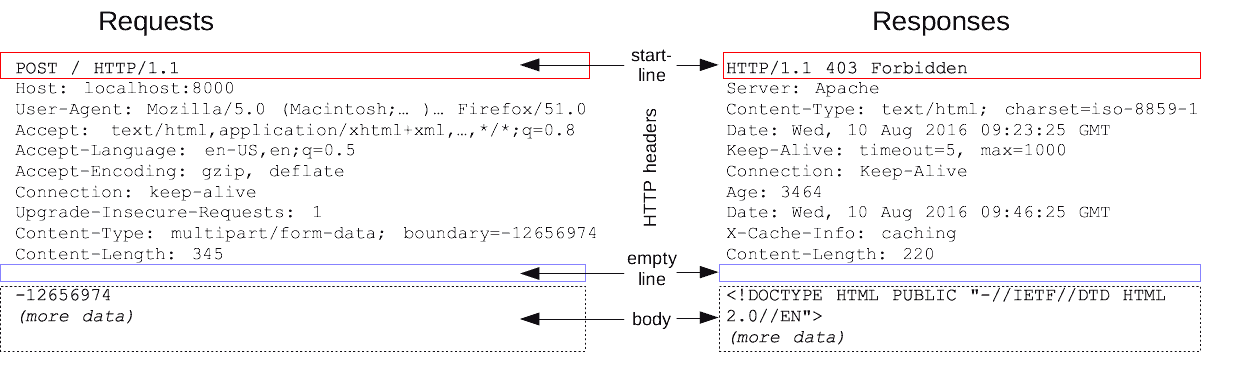
// 요청
OPTIONS /api/data HTTP/1.1
Host: api.example.com
Origin: https://example.com
Access-Control-Request-Method: POST
Access-Control-Request-Headers: X-Custom-Header
- 브라우저는 preflight request/response를 통해 본 요청이 이뤄질 수 있는지 미리 확인한 후 본 요청을 보낸다.
// 응답
HTTP/1.1 204 No Content
Access-Control-Allow-Origin: https://example.com
Access-Control-Allow-Methods: POST, GET, OPTIONS
Access-Control-Allow-Headers: X-Custom-Header
Access-Control-Max-Age: 600
- 서버는 본 요청에 대해 응답해준다.
POST /api/data HTTP/1.1
Host: api.example.com // 요청을 받는 서버의 호스트
Origin: https://example.com // 요청을 보내는 클라이언트의 출처(도메인)
X-Custom-Header: value
Content-Type: application/json // 요청 본문의 내용 유형을 JSON을 명시
{
"data": "example" // 실제 데이터
}
preflight는 다음과 같은 상황에서 발생한다.
- OPIONS: 브라우저에서 OPTIONS를 던져 해당 사이트에서 사용가능한 method정보를 가져오게 될 때 preflight가 일어난다. 따라서 개발자는 실제 원하는 요청에 대해 작성해주면 되고 OPTIONS request를 보내는 코드를 작성하지 않아도 된다.
methods : GET, POST, OPTIONS, HEAD, PUT, DELETE - Simple Request(단순 요청): 사용자 정의 Header 정보를 추가, 수정하게 되면 단순요청에 preflight가 발생하게 된다. 예외적으로 사용자 정의 Header가 content-type일 때 type이 text/plain, multipart/form-data, x-www-form-urlencoded 일 경우엔 preflight가 일어나지 않는다.
사용자 정의 Header : Accept, Accept-language, content-language, content-type
Simple Request : GET, POST, HEAD- Simple Request를 제외한 나머지 요청
- 쿠키 세팅: 내 쿠키를 다른 third party에 보내고 싶을 때 with Credential을 이용하게 되는데 이 때 preflight가 발생하게 된다.
2. simple request
preflight request를 생략하고 서버에 바로 실제 request를 보낸 후 server가 이에 대한 응답을 헤더에 Access-Control-Allow-Origin header를 보내주면 브라우저가 CORS 정책 위반 여부를 검사하는 방식이다. preflight request를 생략하려면 아래와 같은 조건들이 모두 만족되어야 한다.
- request의 method가 GET, POST, HEAD 중 하나여야 한다.
- request의 header가 Accept, Accept-Language, Content-Language, Content-Type, DPR, Downlink, Save-Data, Viewport-Width, Width인 경우에만 적용된다.
- Conttent-Type 헤더가 application/x-www-form-urlencoded, multipart/form-data, text/plain 중 하나여야 한다.
기본적으로 요즘 HTTP 요청은 application/json 또는 text/xml로 이루어지기에 대부분 3번째 Content-Type 헤더 조건을 만족시키지 못한다. 따라서, preflight request가 이루어지는 경우가 대다수라고 볼 수 있다.
3. credentialed request
client가 server로 요청할 때 자격 인증 정보(Credential) 를 담아서 요청할 때 사용되는 방식이다. 여기서 말하는 자격 인증 정보는 session ID가 저장되어 있는 cookie나 Authorization header에 설정하는 token value 등을 의미한다.
기본적으로 브라우저가 제공하는 요청 API 들은 별도의 option없이 브라우저의 쿠키와 같은 data를 함부로 request data에 담지 않도록 설정되어 있다. 요청에 인증과 관련된 정보를 담을 수 있게 해주는 옵션이 바로 credentials 옵션이다. 이 옵션에는 3가지 값이 있는데 각각 다음과 같은 의미를 갖는다.
- same-origin: 같은 출처 간 요청에만 인증 정보를 담을 수 있음
- include: 모든 요청에 인증 정보를 담을 수 있음
- omit: 모든 요청에 인정 정보를 담을 수 없음
credentials가 include로 설정되어야 Cross Origin 요청이 가능하다.
또한 서버에서도 응답 헤더를 다음과 같이 설정해줘야 한다.
- 응답 헤더의 Access-Control-Allow-Credentials 항목을 true로 설정해야한다.
- 응답 헤더의 Access-Control-Allow-Origin을 *(와일드카드)로 설정하면 안된다
- 응답 헤더의 Access-Control-Allow-Method를 *로 설정하면 안된다.
- 응답 헤더의 Access-Control-Allow-Headers를 *로 설정하면 안된다.
참고로 credentialed request 역시 preflight request가 선행된다.
주의할 점
CORS는 웹 어플리케이션이 출처 간 요청을 안정하게 수행할 수 있도록 하는 메커니즘이다. 브라우저는 보안 상의 이유로 동일 출처 정책을 강제한다. 따라서, 웹 페이지에서 다른 출처의 자원에 접근하려 할 때 CORS 규칙을 따르지 않으면 브라우저는 이를 차단한다.
브라우저는 특정 조건이 충족될 때 preflight request을 서버로 보낸다. 이는 OPTIONS method로 이루어지며, server가 실제 요청을 허용하는지 미리 확인한다. 서버는 이 요청에 대해 허용되는 출처, 메서드, 헤더 등을 응답한다.
그러나 모든 요청이 preflight 요청을 필요로 하지는 않는다. 특히 간단한, GET, POST, HEAD 요청의 경우 특정 조건을 만족하면 preflight 없이 바로 실제 요청이 이루어질 수 있다. 이러한 경우 브라우저는 요청을 보내고, 서버는 응답을 반환한다.
브라우저가 preflight 요청을 생략하고 실제 요청을 보내는 경우, 서버는 이를 처리하고 응답을 반환할 수 있다. 그러나 응답이 CORS 규칙을 위반하면 브라우저는 그 응답을 차단하고 CORS 에러를 발생시킨다.
여기서 중요한 점은, server는 요청을 정상적으로 처리하고 응답을 반환했을 수 있지만, 브라우저는 이를 수신하고 처리하지 않는다는 것이다. 이로 인해 클라이언트 측에서는 요청이 실패한 것처럼 보이지만, 실제로는 서버에서 작업이 이루어졌을 수 있다.
예시 상황
클라이언트가 서버에 POST 요청을 보내 데이터를 업데이트한다고 가정해보자
- 클라이언트가 브라우저에서 server로 POST 요청을 보낸다.
- 서버는 요청을 받아 DB를 업데이트하고, 성공 응답을 반환한다.
- 그러나 서버 응답에 필요한 CORS 헤더가 누락되어 있다.
- 브라우저는 서버의 응답을 CORS 위반으로 간주하고, 응답을 차단하며 CORS 에러를 표시한다.
이 경우, 서버 측에서는 데이터 업데이트가 정상적으로 이루어졌지만, 클라이언트 측에서는 요청이 실패한 것 처럼 보인다. 이는 다음과 같은 문제를 야기할 수 있다.
- 클라이언트는 서버에 대한 작업이 실패했다고 잘못 인식할 수 있다.
- 잘못된 응답 처리를 통해 중복된 요청이 발생할 수 있다.
- 사용자는 잘못된 오류 메시지를 볼 수 있다.
이러한 문제를 방지하려면
- 서버는 CORS 설정을 정확히 구성하여 모든 필요한 헤더를 포함해야 한다.
- 클라이언트는 서버와의 상호작용이 제대로 이루어졌는지 확인하기 위해 네트워크 트래픽을 모니터링할 수 있어야 한다.
- 개발자는 브라우저 콘솔의 CORS 에러 메시지를 주의 깊게 분석하여 문제를 정확히 파악해야 한다.
이와 같은 이해를 통해 CORS 에러가 발생했을 때, 단순히 요청이 실패했다고 가정하지 않고, 서버와 클라이언트 사이의 실제 상호작용을 면밀히 조사해야 한다.
출처
https://velog.io/@cloudlee711/CORS-%EC%99%80-preflight
https://bskyvision.com/entry/CORS%EC%99%80-%EA%B4%80%EB%A0%A8-%EC%9E%88%EB%8A%94-preflight-request%EB%9E%80
https://yoonlangcow.tistory.com/44
'인터넷 기본 지식' 카테고리의 다른 글
| #10. JWT (0) | 2024.06.24 |
|---|---|
| #9. RESTful 웹 API 디자인 (1) | 2024.06.19 |
| #8. LSP (2) | 2024.06.10 |
| #7. 프로그래밍 패러다임 (1) | 2024.06.09 |
| #6. DNS(Domain Name System) (0) | 2024.05.31 |