What is network security?
기밀성(Confidentiality)
- 정의: 메시지의 내용은 발신자와 수신자만 "이해"할 수 있어야 한다.
- 방법
- 발신자가 메시지를 암호화함(Sender Encrypts Message): 발신자는 메시지를 암호화하여 전송한다.
- 수신자가 메시지를 복호화함(Receiver Decrypts Message): 수신자는 메시지를 복호화하여 내용을 확인한다.
인증(Authentication)
정의: 발신자와 수신자는 서로의 신원을 확인하고자 한다.
목적: 메시지를 주고받은 양쪽이 서로의 신원을 확인하여 신뢰성을 확보한다.
메시지 무결성(Message Integrity)*
정의: 발신자와 수신자는 메시지가 변조되지 않았음을 확인하고자 한다.
목적: 메시지가 전송되는 동안 또는 이후에 변경되지 않았음을 보장하여 데이터의 무결성을 유지한다.
접근성 및 가용성(Access and Availability)*
정의: 서비스는 사용자에게 접근 가능하고 사용 가능해야 한다.
목적: 네트워크 서비스가 항상 접근 가능하고 가용성을 유지하여 사용자들이 필요할 때 사용할 수 있도록 한다.
Friends and enemies: Alice, Bob, Trudy

밥과 앨리스는 아래의 것들이 될 수 있다.
- 실생활의 밥과 앨리스
- 웹 브라우저/서버
- 온라인 뱅킹 클라이언트/서버
- DNS 서버
- BGP 라우터
- 기타 예시
There are bad guys(and girls) out there!
- 엿듣기(Eavesdrop)
- 메시지를 가로채는 행위
- 메시지 삽입(Actively Insert Messages into Connection)
- 연결에 메시지를 적극적으로 삽입하는 행위
- 사칭(Impersonation)
- 패킷의 소스 주소 또는 다른 필드를 속여서(fake) 사칭하는 행위
- 하이재킹(Hijacking)
- 진행 중인 연결을 장악하여 발신자나 수신자를 제거하고 자신을 그 자리에 삽입하는 행위
- 서비스 거부(Denial of Service)
- 자원을 과부하 시켜 다른 사용자가 서비스를 이용하지 못하게 하는 행위
The language of cryptography
- 평문(Plaintext)
- 암호화 키(Encryption Key) - KA
- 암호화 알고리즘(Encryption Alogrithm)
- 암호문(Ciphertext)
- 복호화 키(Decryption Key) - KB
- 복호화 알고리즘(Decryption Algorithm)
- 메시지(m)
- 원본 평문 메시지
Breaking an encryption scheme
암호문만 있는 공격(Ciphertext-Only Attack)
- 정의: 트루디가 분석할 수 있는 암호문만을 가지고 있는 공격 유형
- 두 가지 접근법
- 무차별 대입 공격: 모든 가능한 키를 검색하여 암호를 해독하려는 시도
- 통계 분석: 암호문에서 나타나는 빈도나 패턴을 분석하여 암호를 해독하려는 시도
알려진 평문 공격
- 정의: 트루디가 암호문에 대응하는 평문을 알고 있는 공격 유형
- 예시
- 단일 알파벳 암호(Monoalphabetic Cipher)에서 트루디는 특정 문자와 암호문의 대응을 파악할 수 있습니다. 예를 들어, a, l, i, c, e, b, o 등의 문자에 대한 대응을 찾아낼 수 있습니다.
선택된 평문 공격
- 정의: 트루디가 선택한 평문에 대한 암호문을 얻을 수 있는 공격 유형.
- 설명: 트루디는 특정 평문을 선택하고, 그 평문이 암호화된 결과(암호문)를 분석하여 암호를 해독하려고 시도합니다.
Symmetric key Cryptography
Simple Encryption Scheme
치환 암호(Substitution Cipher)
- 정의: 하나의 문자를 다른 문자로 대체하여 암호화하는 방식
단일 알파벳 치환 암호(Monoalphabetic Cipher)
- 정의: 각 문자를 고유한 다른 문자로 대체한다. 예를 들어, 알파벳 a는 항상 특정한 문자로 바뀐다.

Encryption key: 26개의 문자를 다른 26개의 문자로 매핑하는 규칙
A more Sophisticated encryption approach
n개의 치환 암호
- 다중 치환 암호를 사용한다. 각 치환 암호는 서로 다른 규칙으로 문자를 치환한다.
순환 패턴(Cycling Pattern)
- 치환 암호를 순환적으로 사용한다.
- 예를 들어, n=4 일 때, 치환 암호의 사용 순서는 M₁, M₃, M₄, M₃, M₂와 같이 반복된다.
- 이 패턴에 따라 각 새로운 평문 문자에 대해 다음 치환 암호를 사용한다.
평문 문자에 대한 순환적 치환
- 예를 들어, dog라는 단어를 암호화할 때
- d, M1에 의해 치환
- o, M3에 의해 치환
- g, M4에 의해 치환
- 예를 들어, dog라는 단어를 암호화할 때
암호화 키
- 암호화 키는 n개의 치환 암호와 순환 패턴으로 구성된다.
- 이 키는 단순히 n-bit 패턴만을 포함하는 것이 아니라, 각 치환 암호와 그 순서를 포함한다.
Symmetric key crypto: DES
DES(Data Encrpyion Standard)
- 56비트 대칭 키를 사용하여 64비트 평문 입력을 암호화
- 블록 암호화 기법을 사용하며, 암호 블록 체이닝(CBC) 방식을 포함
DES 보안성
- DES Challenge
- 56비트 키로 암호화된 문구가 브루탈 포스 공격(모든 키를 대입해 찾는 방법)으로 하루 안에 해독된 사례가 있음
- 현재까지 알려진 좋은 분석 공격 방법은 없음
- 아직 DES를 효과적으로 분석하여 해독하는 좋은 공격 방법이 알려져 있지 않음
DES의 보안 강화
- 3DES(Triple DES)
- DES의 보안성을 높이기 위해 개발된 방법
- 데이터를 세 가지 다른 키를 사용하여 세 번 암호화
- 이 방법으로 DES의 보안성을 크게 강화할 수 있음
AES: Advance Encryption Standard4
AES
- 대칭 키 NIST 표준: DES를 대체하여 2001년 11월에 채택됨
- 데이터를 128비트 블록 단위로 처리
- 키 길이는 128.192 또는 256비트가 처리
AES의 보안성
- 브루탈 포스 복호화
- DES의 경우 각 키를 시도하여 복호화하는 데 1초가 걸리는 반면, AES를 브루트 포스로 복호화하는 데는 149조 년이 걸림
- 이는 AES가 DES보다 훨씬 더 강력한 보안을 제공한다는 것을 의미함
- 브루탈 포스 복호화
Public Key Cryptography
대칭 키 암호화
- 필요한 요소: 송신자와 수신자가 공유된 비밀 키를 알고 있어야 함
- 문제점: 키를 처음에 어떻게 동의할 것인가? 특히 서로 만난 적이 없을 때
공개 키 암호화
- 공개 암호화 키: 모든 사람에게 공개됨
- 개인 복호화 키: 오직 수신자만 알고 있음
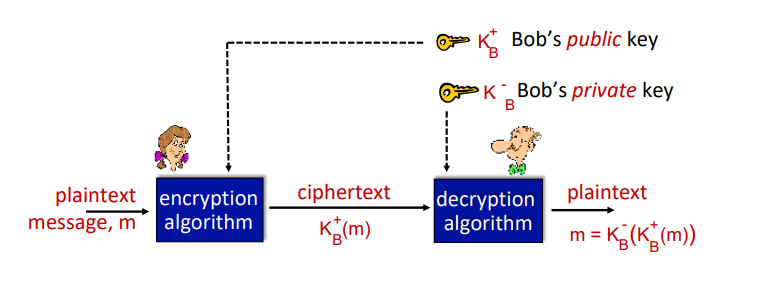
Public key encryption algorithms
공개 키 암호화의 요구 사항
암호화 및 복호화 함수
- 공개 키 암호화 함수와 개인 키 복호화 함수의 쌍이 필요하다. 이 함수들은 다음과 같은 관계를 가져야 한다.

- 공개 키 암호화 함수와 개인 키 복호화 함수의 쌍이 필요하다. 이 함수들은 다음과 같은 관계를 가져야 한다.
보안 조건
- 공개 키가 주어졌을 때, 이를 통해 개인 키를 계산하는 것이 매우 어려워야 한다. 이는 누군가가 공개 키에 접근할 수 있더라도 개인 키 없이는 메시지를 복호화할 수 없음을 보장한다.
RSA 알고리즘
- RSA 알고리즘은 그 발명가인 Rivest, Shamir, Adleman의 이름을 따서 명명된 공개 키 암호화 알고리즘이다.
RSA: getting ready
- 메시지: 단순히 비트 패턴
- 비트 패턴: 고유하게 정수로 표현 가능
- 따라서 메시지를 암호화하는 것은 정수를 암호화하는 것과 동일
- 예제
- 예시 메시지 m: m = 10010001
- 이 메시지는 10진수로 145로 고유하게 표현 가능
- m을 암호화하기 위해, 해당 숫자를 암호화하면 새로운 숫자 (암호문)를 얻게 됨
RSA: Creating public/private key pair
- 두 개의 큰 소수 p, q 선택
- e.g. 각각 1024 비트 길이의 소수 p와 q를 선택
- n과 z 계산
- n = pq
- z = (p-1)(q-1)
- e 선택
- e를 n보다 작으면서 z와 서로 소인 값을 선택한다.
- e와 z는 공통 인수가 없어야 한다.
- d 선택
- d는 ed-1이 z로 정확히 나누어 떨어지도록 선택한다.
- 즉, ed mod z = 1이 성립해야 한다.
- 공개 키와 비밀 키 설정
- 공개 키: (n, e)
- 비밀 키: (n, d)
RSA: encryption, decryption
키 생성:
- n, e: 공개 키
- n, d: 비밀 키
메시지 암호화
- m이 n 보다 작은 메시지라고 가정하자
- 메시지 m을 암호화하려면 다음을 계산한다.
- c = me mod n
- 여기서 c는 암호화된 메시지이다.
- c = me mod n
메시지 복호화
- 수신된 암호화된 비트 패턴 c를 복호화하려면 다음을 계산한다..
- m = cdmod n
- 여기서 m은 복호화된 원래 메시지이다.

- 수신된 암호화된 비트 패턴 c를 복호화하려면 다음을 계산한다..
RSA: example
설정 단계
두 개의 소수 p와 q 선택
- p = 5
- q = 7
두 소수의 곱 n 계산
- n = pq = 5 * 7 = 35
오일러의 토션트 z 계산
- z = (p-1)(q-1) = (5-1)(7-1) = 4 * 6 = 24
암호화 지수 e 선택
- e = 5(조건: e와 z는 서로소여야 함)
5. 복호화 지수 d 계산
- d = 29(조건: ed mod z = 1)

Why does RSA work?
RSA 알고리즘의 작동 원리를 이해하려면 cd mod n = m을 증명해야 한다. 여기서 c는 c = me mod n 이다.
기본 사실
- 임의의 x와 y에 대해, 다음이 성립한다.

- 여기서 n = pq이고 z = (p-1)(q-1)이다.

RSA: another important property
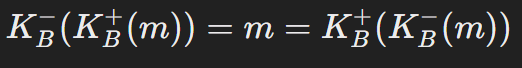
- KB+는 Bob의 공개 키이다.
- KB-는 Bob의 개인 키이다.
- m은 원문 메시지(평문)이다.
- 공개 키로 먼저 암호화하고 개인 키로 복호화
- 개인 키로 먼저 암호화하고 공개 키로 복호화
Why is RSA secure?
Bob의 공개 키
- 공개 키 (n, e)는 모두에게 알려져 있다.
- n은 두 개의 큰 소수 p와 q의 곱으로 생성된다.
비밀 키 d의 추정 난이도
- d는 비밀 키로서, d를 알면 메시지를 복호화할 수 있다.
- d를 찾으려면 n의 소인수 p와 q를 알아야 한다.
- 하지만 n만 알고 있을 때 p와 q를 찾는 것은 매우 어렵다.
소인수 분해의 어려움
- 큰 수의 소인수분해는 현재의 계산 능력으로는 매우 어렵다.
- RSA의 보안은 이 수학적 문제의 어려움에 기반한다.
RSA in practice: session keys
RSA의 계산 복잡도
- RSA에서 지수 연산은 매우 계산 집약적이다.
- 대칭키 암호화 방식인 DES는 RSA보다 적어도 100배 빠르다.
세션 키 사용 이유
- 공개 키 암호화를 사용하여 안전한 연결을 설정한다.
- 그런 다음 데이터를 암호화하기 위해 두 번째 키인 대칭 세션 키를 설정한다.
세션 키 Ks
- Bob의 Alice는 RSA를 사용하여 대칭 세션 키 Ks를 교환한다.
- 두 사람이 모두 Ks를 갖게 되면, 그 후부터는 대칭키 암호화를 사용하여 데이터를 암호화한다.
RSA는 세션 키를 교환하는 데 사용되고, 이후의 데이터 암호화는 더 빠른 대칭키 암호화 방식(DES)을 사용하여 수행된다. 이를 통해 보안성과 효율성을 동시에 유지할 수 있다.
Authentication
Bob은 Alice가 자신의 신원을 증명하기를 원한다.
프로토콜 ap 1.0
- alice는 "나는 Alice입니다." 라고 말한다.
- 문제점: 네트워크 상에는 Bob이 Alice "볼 수" 없기 때문에 Trudy가 단순히 자신을 Alice라고 선언할 수 있습니다.
프로토콜 ap 2.0
- alice는 자신의 소스 IP 주소를 포함하는 IP 패킷에서 "나는 alice입니다."라고 말한다.
- 문제점: trudy는 alice의 주소를 스푸핑하여 패킷을 만들 수 있다.
프로토콜 ap 3.0
- Alice는 "나는 Alice입니다"라고 말하며 자신의 비밀번호를 Bob에게 보낸다.
- 문제점: Trudy는 Alice의 IP주소와 비밀번호를 도청할 수 있는 경우, Trudy는 Alice인 것처럼 자신을 가장할 수 있다.
프로토콜 ap4.0
- Alice가 실시간임을 증명하기 위해, Bob은 Alice에게 넌스 R을 보낸다.
- nonce: 단 한 번만 사용되는 일회성 번호(R)를 사용한다.
- Alice는 R을 공유 비밀 키로 암호화하여 반환해야 한다.
- 프로토콜 과정
- Alice가 Bob에게 "나는 Alice입니다"라고 말한다.
- Bob은 Alice에게 넌스 R을 보낸다.
- Alice는 R을 공유 비밀 키 KA-B로 암호화한 후 Bob에게 보낸다.
- Bob은 받은 암호화된 R을 공유 비밀 키로 복호화하여 보낸 R과 일치하는지 확인한다.
프로토콜 ap5.0
- ap4.0 프로토콜에서는 공유 대칭 키를 사용해야 했다.
- 여기서 공개 키 암호화를 사용하여 인증할 수 있는 지 확인해보자.
- 프로토콜 과정
- alice의 주장: alice가 bob에게 '나는 alice 입니다'라고 말한다.
- bob의 넌스 전송: bob은 alice에게 넌스 r을 보낸다.
- Alice의 응답:
- Alice는 Bob이 보낸 넌스 R을 자신의 개인 키로 암호화하여 Bob에게 돌려보낸다.
- 공개 키 요청
- Bob은 Alice에게 공개 키를 보내달라고 요청한다.
- Alice의 공개 키 전송
- Alice는 자신의 공개 키를 Bob에게 보낸다.
- Bob의 검증
- Bob은 Alice의 공개 키로 복호화하여 원래의 넌스 R을 얻는다.
Authentication: ap5.0 - there's still a flaw!
문제
- 중간자 공격(Man-in-the-Middle Attack): Trudy가 Bob에게는 Alice로, Alice에게는 Bob으로 가장한다.
시나리오
- Alice의 주장
- Alice가 Bob에게 "나는 Alice입니다"라고 말함
- Bob의 넌스 전송
- Bob은 Alice에게 넌스 R을 보낸다.
- Trudy의 개입
- Trudy가 Alice와 Bob의 통신을 가로채어 각각의 통신을 관리한다.
- Trudy가 Bob에게 "나는 Alice입니다."라고 말한다.
- Trudy가 Bob의 넌스를 받아서 자신이 가지고 있는 개인 키로 암호화한다.
- 공개 키 요청
- Bob이 Trudy(Alice로 가장한)에게 공개 키를 요청한다.
- Trudy는 자신의 공개 키를 보낸다.
- Bob의 검증
- Bob은 Trudy의 공개 키를 사용하여 넌스를 검증한다.
- Bob은 Trudy가 Alice라고 생각하게 된다
- Bob의 메시지 전송
- Bob은 개인 메시지 m을 Trudy(Alice로 가장한)에게 보낸다.
- Trudy는 이 메시지를 복호화하여 내용 m을 알아낸다.
- Trudy의 개입
- Trudy는 Alice에게 "나는 Bob입니다."라고 말한다.
- Alice는 Trudy가 Bob이라고 생각하고 메시지를 주고 받는다.
- Trudy가 Bob의 메시지를 Alice에게 전달한다.
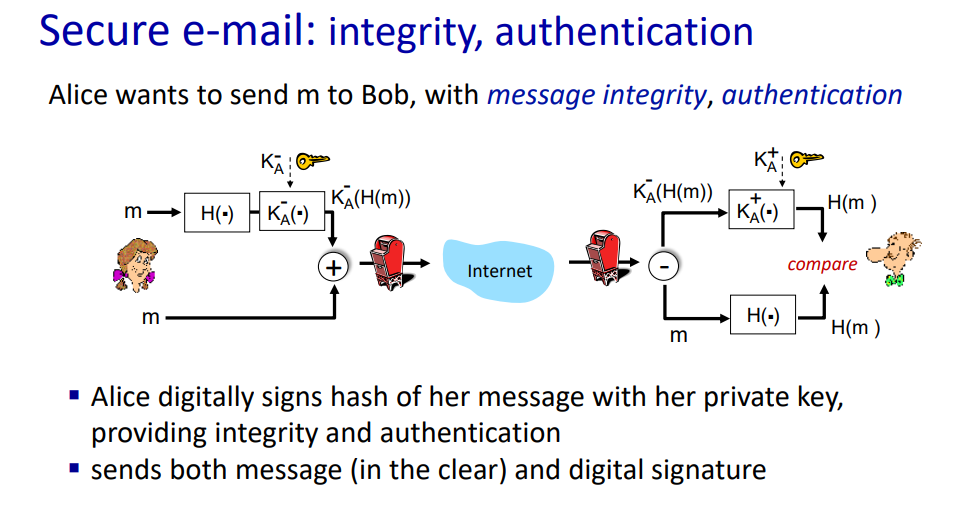
Message Integrity
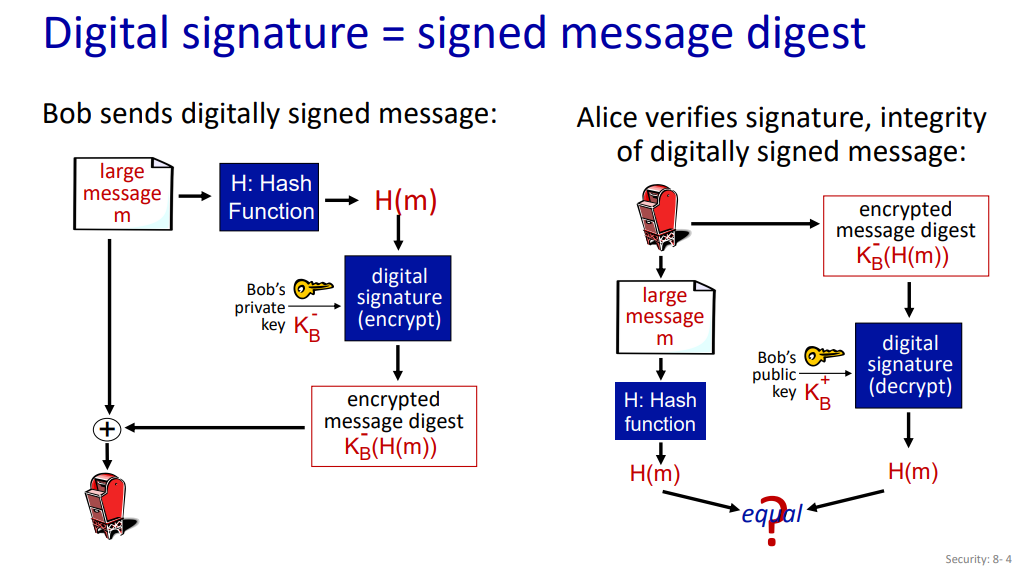
Digital Signatures
- 서명자(Bob)가 문서에 디지털 서명을 한다.
- 문서의 소유자이자 작성자인 Bob이 디지털 서명을 하게 된다.
- 검증 가능하고 위조 불가능
- 수신자(Alice)는 Bob이 서명했음을 증명할 수 있다.
- Alice를 포함한 누구도 Bob의 서명을 위조할 수 없다.
- 메시지 m에 대한 간단한 디지털 서명
- Bob은 자신의 개인 키를 사용하여 메시지 m을 암호화함으로써 서명된 메시지를 만든다.
- 이는 Bob의 서명이 포함된 메시지로서, 누구든지 Bob의 공개 키를 사용하여 서명을 검증할 수있다.예시 상황

- Alice가 Bob으로부터 서명된 메시지 m과 서명을 받는다.
검증 과정 1. 서명 검증 - Alice는 Bob의 공개 키를 사용하여 서명을 복호화한다. - 복호화 결과가 메시지 m과 일치하는지 확인한다.
2. **확인 내용** - 복호화 했을 때 같이 전달된 m과 일치하면, 서명자는 Bob의 개인 키를 사용했다는 의미이다. - 이를 통해 Alice는 다음을 확인할 수 있다. - 메시지 m은 Bob이 서명했다. - 다른 누구도 아닌 Bob이 서명했다. - Bob이 서명한 메시지는 m이며, 다른 메시지 m'이 아니다.
3. **부인 방지** - Alice는 메시지 m과 서명을 법원에 제출하여 Bob이 서명했음을 증명할 수 있다 - 이는 Bob이 해당 메시지를 서명했다는 사실을 부인할 수 없게 만든다.
Message Digests
메시지 다이제스트는 긴 메시지를 공개 키 암호화로 처리하는 것은 계산 비용이 많이 들기 때문에 고안된 방법이다. 메시지 다이제스트는 고정 길이의 디저털 지문을 생성하는데 사용된다.
목표: 고정 길이이며 계산이 쉬운 디지털 "지문"을 생성하는 것이다.
방법: 해시 함수 H를 메시지 m에 적용하여 고정 길이의 메시지 다이제스트 H(m)를 얻는다.
해시 함수의 속성
- Many-to-1: 여러 입력값이 동일한 출력값을 가질 수 있다.
- 고정 크기 메시지 다이제스트: 고정 크기의 다이제스트(또는 지문)을 생성한다.
- 역산 불가능성: 주어진 메시지 다이제스트 x에 대해, x = H(m)을 만족하는 m을 찾는 것은 계산적으로 불가능하다.
Internet checksum: poor crypto hash function
인터넷 체크섬의 특성
- 고정 길이 다이제스트 생성: 메시지의 16비트 합을 사용하여 고정 길이의 다이제스트를 생성한다.
- Many-to-One: 여러 개의 다른 메시지가 동일한 체크섬 값을 가질 수 있다.
하지만, 주어진 해시 값(체크섬 값)을 가지고 동일한 해시 값을 가지는 다른 메시지를 쉽게 찾을 수 있다. 이는 인터넷 체크섬이 강력한 암호화
해시 함수로 사용되기에 부적합하다는 것을 의미한다.

Digital signature = signed message digest
MD5 해시 함수
- 특징
- 128비트 메시지 다이제스트를 생성한다.
- 4단계 과정을 통해 메시지 다이제스트를 계산한다.
- 임의의 128비트 문자열 x에 대해, MD5 해시가 x와 동일한 메시지 m을 구성하는 것은 매우 어렵다.
- 사용 예
- 파일의 무결성을 확인하기 위해 사용된다.
- 패스워드 저장 및 검증 등에 사용되었으나, 현재는 보안 취약성 때문에 사용이 권장되지 않는다.
- 특징
SHA-1(Secure Hash Algorithm 1)
- 특징
- 미국 표준으로 채택되었다.
- 160비트 메시지 다이제스트를 생성한다.
- 사용 예
- 디지털 서명, 인증서, SSL/TLS 등의 보안 프로토콜에서 사용된다.
- 현재는 보안 취약성으로 인해 SHA-256 등 더 강력한 해시 알고리즘으로 대체되고 있다.
- 특징
Authentication: ap5.0 - let's fix it!
중간자 공격 시나리오
Trudy가 Alice로 가장하여 Bob에게 접근
- Alice가 "I am Alice"라고 선언
- Bob이 nonce R를 Alice에게 보낸다.
- Trudy가 이 nonce R을 가로챈다.
- Trudy는 Alice의 공개 키를 사용하여 nonce R을 암호화하고, 이를 Bob에게 보낸다.
- Bob는 Trudy가 보낸 것(Alice의 공개 키를 사용하여 nonce R을 암호화)을 확인하고, Alice라고 믿는다.
Trudy가 Bob으로 가장하여 Alice에게 접근
- Trudy는 nonce R를 Alice에게 보낸다.
- Alice는 Trudy가 보낸 R를 자신의 비밀 키로 암호화하여 Trudy에게 보낸다.
- Trudy는 Alice의 비밀 키를 이용해 R를 복호화하여 원래의 메시지를 획득한다.
해결 방법(슬라이드의 설명)
공개 키의 확인 과정에서 문제가 발생
- Trudy는 Alice로부터 공개 키를 요청하고, 이를 악용하여 중간자 공격을 수행한다.
- Bob이 Alice의 공개 키를 확인하는 과정에서 Trudy의 공개 키로 바꿔치기 할 수 있다.
비밀 키와 공개 키의 올바른 사용
- Bob은 Alice의 공개 키를 사용할 때 이를 검증해야 한다.
- Alice와 Bob은 공개 키가 올바른지 확인하는 추가적인 보안 절차를 가져야 한다.
Need for certified public keys
동기: Trudy가 Bob에게 피자 장난을 친다.
- Trudy가 Bob에게 피자 장난을 치는 시나리오를 통해 인증된 공개 키의 필요성을 설명한다.
시나리오
- Trudy가 이메일 주문을 작성
- trudy는 피자 가게에 보낼 이메일 주문을 작성한다.
- trudy는 이 주문서를 자신의 비밀 키로 서명한다.
- Trudy가 피자 주문서를 피자 가게로 보낸다.
- trudy는 서명된 주문서를 피자 가게에 보낸다.
- Trudy가 피자 가게에 공개 키를 보낸다.
- trudy는 피자 가게에 자신의 공개 키를 보내지만, 이를 Bob의 공개 키라고 속인다.
- 피자 가게가 서명을 검증
- 피자 가게는 trudy가 보낸 공개 키를 사용해 서명을 검증하고, 서명이 유효하다고 판단하여 Bob에게 페퍼로니 4판을 배달한다.
- 결과
- Bob은 주문하지도 않은 피자를 받는다.
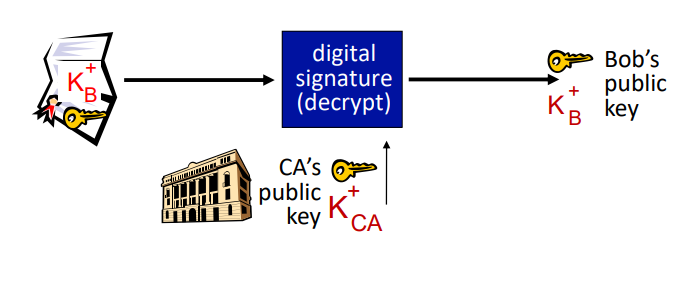
Public key Certification Authorities(CA)
정의
- 인증 기관(Certification Authority,CA): 특정 엔터티(개인, 웹사이트, 라우터 등)에 공개 키를 연결해주는 기관
과정
엔터티가 공개 키를 CA에 등록
- 엔터티(e.g. Bob)가 자신의 공개 키와 식별 정보를 CA에 제공한다.
- CA는 Bob이 제공한 식별 정보와 공개 키를 검증한다.
CA가 인증서 생성
- CA는 Bob의 공개 키와 Bob의 식별 정보를 바인딩한 인증서를 생성한다.
- 인증서는 CA의 비밀키로 디지털 서명된다.
인증서 발급
- CA는 서명된 인증서를 Bob에게 발급합니다.
- 인증서에는 Bob의 공개 키와 CA의 서명이 포함됩니다.
인증서의 역할
- 인증서의 주요 역할은 CA가 "이것은 Bob의 공개 키입니다"라고 보증하는 것이다.
- 다른 엔터티는 CA의 공개 키를 사용하여 인증서의 서명을 검증할 수 있다.
- 이를 통해 다른 엔터티는 Bob의 공개 키가 진짜임을 신뢰할 수 있다.
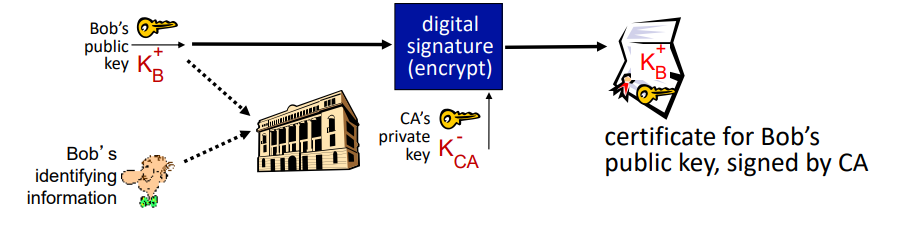
Public key Certification Authorities(CA)
목표: Alice가 Bob의 공개 키를 필요로 할 때, 이를 신뢰할 수 있는 방법을 얻는 과정
과정
Bob의 인증서 획득
- Alice는 Bob이나 다른 출처에는 Bob의 인증서(certification)를 얻는다.
- 이 인증서에는 Bob의 공개 키가 포함되어 있다.
CA의 공개 키를 사용한 검증
- Alice는 CA의 공개 키를 사용하여 인증서에 있는 디지털 서명을 검증한다.
- 인증서를 검증함으로써, 인증서에 포함된 Bob의 공개 키가 실제로 Bob의 것임을 확인 할 수 있다.
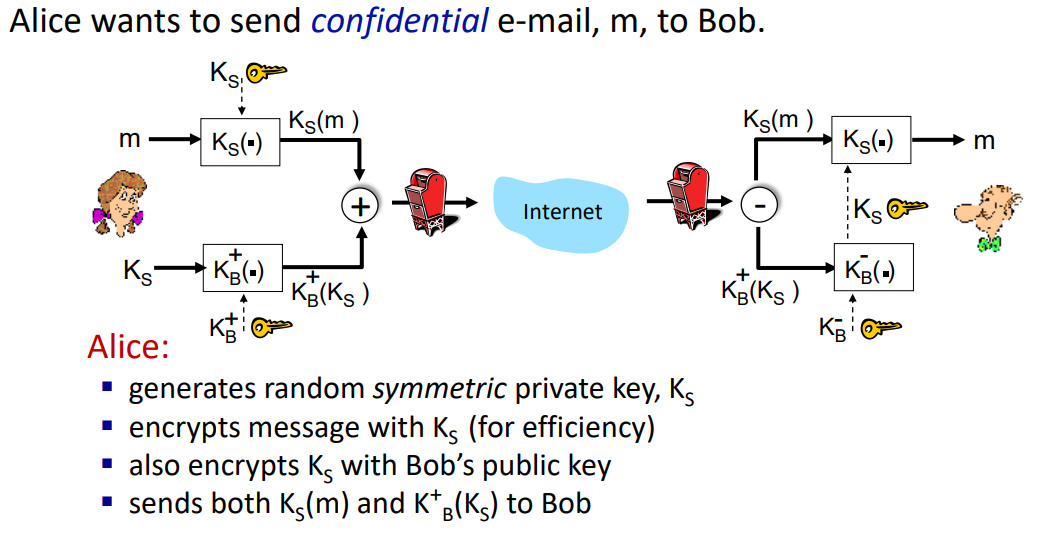
Secure e-mail: confidentiality
Alice는 Bob에게 기밀 이메일 m을 보내려 할 때, 다음과 같은 절차를 따른다.
Secure e-mail: integrity, authentication
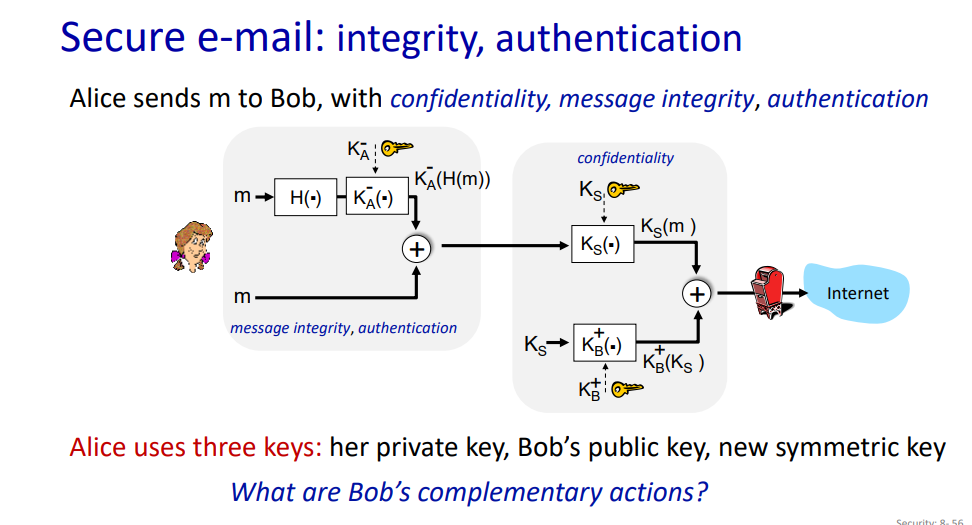
Securing TCP connections: TLS
Transport-layer security(TLS)
TLS는 전송 계층 위에 배치된 보안 프로토콜로, 거의 모든 브라우저와 웹 서버(port 443)에서 지원된다. 이 프로토콜은 다음과 같은 보안 기능을 제공한다.
기밀성(Confidentiality)
- 대칭 암호화(Symmetric Encryption)를 통해 제공된다. 대칭 암호화는 빠르고 효율적이며, 송신자와 수신자가 동일한 키를 사용하여 데이터를 암호화하고 복호화한다.
무결성(Integrity)
- 암호화 해시(Cryptographic Hashing)를 통해 제공된다. 암호화 해시는 데이터가 전송되는 동안 변조되지 않았음을 보장하는 역할을한다.
인증(Authentication)
- 공개 키 암호화(Public Key Cryptography)를 통해 제공된다. 공개 키 암호화는 송신자와 수신자가 서로의 신원을 확인하고 인증하는데 사용된다.
Transport-layer security: what's needed?
TLS(Transport-Layer Security) 프로토콜을 구성하기 위한 필요한 요소들을 설명한다.
구성요소
- Handshake(핸드셰이크)
- 역할: Alice와 Bob이 서로의 인증서를 사용하여 서로를 인증한다.
- 과정: 서로의 개인 키를 사용하여 공유 비밀을 교환하거나 생성한다.
- Key Derivation(키 유도)
- 역할: Alice와 Bob이 공유 비밀을 사용하여 여러 개의 키를 도출한다.
- 과정: 도출된 키는 이후 통신에서 데이터 암호화에 사용된다.
- Data Transfer(데이터 전송)
- 역할: 데이터를 연속적인 레코드의 형태로 스트리밍하여 전송한다.
- 특징: 단일 거래가 아닌 지속적인 데이터 전송을 지원한다.
- Connection Closure(연결 종료)
- 역할: 연결을 안전하게 종료하기 위해 특별한 메시지를 사용한다.
- 과정: 안전한 연결 종료를 보장하여 데이터 유출을 방지한다.
t-tls: initial handshake
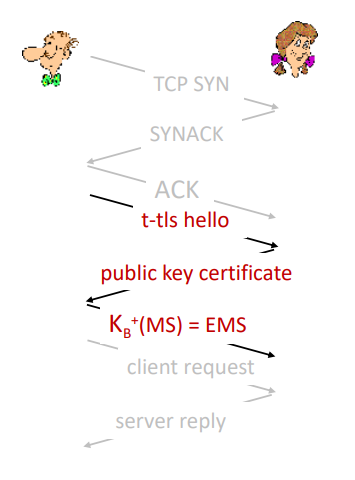
t-tls 핸드셰이크 단계
- TCP 연결 설정
- 과정: Bob이 Alice와 TCP 연결을 설정한다.
- 단계: TCP SYN -> SYNACK -> ACK
- 인증 과정
- 과정: Bob이 Alice가 진짜 Alice인지 확인
- 단계: t-tls hello 메시지를 보낸다.
- 공개 키 인증서 교환
- 과정: Alice는 자신의 공개 키 인증서를 Bob에게 보낸다.
- 단계: 공개 키 인증서 전송
- 마스터 비밀 키 (MS) 전송
- 과정: Bob이 Alice에게 마스터 비밀 키(MS)를 보낸다. 이 키는 TLS 세션에서 다른 모든 키를 생성하는 데 사용된다.
- 단계: Bob은 자신의 비밀 키로 MS를 암호화하여 전송한다.
- 클라이언트 요청 및 서버 응답
- 과정: Alice는 클라이언트 요청을 보내고, Bob은 서버 응답을 보낸다.
- 단계: client request -> server reply
잠재적 문제점
- 3 RTT(Round Trip TIme)
- 설명: 클라이언트가 데이터를 받기 시작하기 전까지 3번의 RTT가 필요하다(TCP 핸드셰이크 포함)
- 영향: 데이터 전송 시작까지의 지연이 발생할 수 있다.
t-tls: cryptographic keys
키 사용 원칙
- 한 키를 여러 암호화 기능에 사용하는 것은 좋지 않음
- 각기 다른 암호화 기능에 동일한 키를 사용하는 것은 보안상 위험할 수 있다.
- 메시지 인증 코드 (MAC)와 암호화에 다른 키를 사용해야 한다.
네 가지 키
- Kc:
- 설명: 클라이언트에서 서버로 전송되는 데이터의 암호화 키
- 사용 목적: 클라이언트에서 서버로 전송되는 데이터를 암호화
- Mc:
- 설명: 클라이언트에서 서버로 전송되는 데이터의 MAC 키
- 사용 목적: 클라이언트에서 서버로 전송되는 데이터의 무결성을 확인
- Ks:
- 설명: 서버에서 클라이언트로 전송되는 데이터의 암호화 키
- 사용 목적: 서버에서 클라이언트로 전송되는 데이터를 암호화
- Ms:
- 설명: 서버에서 클라이언트로 전송되는 데이터의 MAC 키
- 사용 목적: 서버에서 클라이언트로 전송되는 데이터의 무결성을 확인
키 파생 함수(KDF)에서 키 생성
- 설명
- 키는 키 파생 함수(KDF)를 통해 파생된다.
- 마스터 비밀 키(master secret)와 추가적인 랜덤 데이터를 사용하여 새로운 키를 생성
t-tls: encrypting data
- TCP는 데이터 바이트 스트림 추상화를 제공한다.
- 질문: TCP 소켓에 쓰여진 데이터가 실시간으로 암호화될 수 있을까요?
- 답변: MAC(메시지 인증 코드)을 어디에 두어야 할까요? 만약 MAC이 데이터 끝에 있다면, 모든 데이터가 수신되고 연결이 종료될 때까지 메시지 무결성이 보장되지 않는다.
솔루션
- 스트림을 여러 "레코드" 시리즈로 분할
- 각 클라이언트-서버 레코드는 MAC을 포함하고 있으며, 이는 Mc를 사용하여 생성된다.
- 수신자는 도착하는 각 레코드에 대해 동작을 수행할 수 있다.
t-tls 레코드 암호화
t-tls 레코드는 대칭 키 Kc를 사용하여 암호화되며, 이는 TCP에 전달된다.
레코드 형식은 다음과 같다.
- length: 데이터의 길이
- data: 실제 데이터
- MAC: 메시지 인증코드

t-tls: encrypting data(more)
데이터 스트림에 대한 가능한 공격
- 재정렬(re-ordering)
- 공격자가 중간에서 TCP 세그먼트를 가로채고 순서를 재조정한다.
- 암호화되지 않은 TCP 헤더의 시퀀스 번호를 조작하여 발생한다.
- 재전송(replay)
- 이전에 전송된 메시지를 다시 재전송하는 공격이다.
솔루션
- TLS 시퀀스 번호 사용
- 데이터와 TLS 시퀀스 번호를 포함하여 MAC에 통합한다.
- 이를 통해 메시지 순서와 무결성을 보장한다.
- nonce 사용
- 각 메시지에 고유한 nonce(임의의 일회성 숫자)를 포함시켜 재전송 공격을 방지한다.
- nonce는 매번 다른 값을 가지므로, 동일한 메시지가 재전송되더라도 nonce가 달라져 무효화된다.
t-tls 연결 종료(connection close)
- 잘림 공격(truncation attack)
- 공격 방식: 공격자가 TCP 연결 종료 세그먼트를 위조한다.
- 결과: 한쪽 또는 양쪽이 실제보다 적은 데이터가 존재한다고 생각하게 만든다.
- 해결책(solution)
- 레코드 유형 도입
- 유형 0: 데이터 전송을 위한 레코드
- 유형 1: 연결 종료를 위한 레코드
- MAC 계산 방법: 이제 데이터, 유형, 시퀀스 번호를 사용하여 MAC을 계산한다.
- 레코드 유형 도입
- MAC 계산식: Kc(length,type,data,MAC)

Transport-layer security(TLS)
- TLS의 역할
- TLS는 애플리케이션이 사용할 수 있는 API를 제공한다.
- 보안 계층으로 작동하여 어플리케이션 간의 데이터 전송을 보호한다.
- HTTP 관점에서 본 TLS
- HTTP 1.0: 전통적인 HTTP 프로토콜, 암호화되지 않은 텍스트 전송
- HTTP/2: 향상된 성능과 효율성을 제공하는 HTTP 프로토콜
- HTTP/2 + TLS: HTTP/2를 TLS 위에 구현하여 데이터 전송의 보안성을 강화
- HTTP/2(슬림버전) + QUIC: UDP를 기반으로 한 QUIC 프로토콜을 사용하여 더 빠르고 효율적인 연결을 제공
- HTTP/3: HTTP/2의 슬림 버전과 QUIC을 결합한 최신 프로토콜
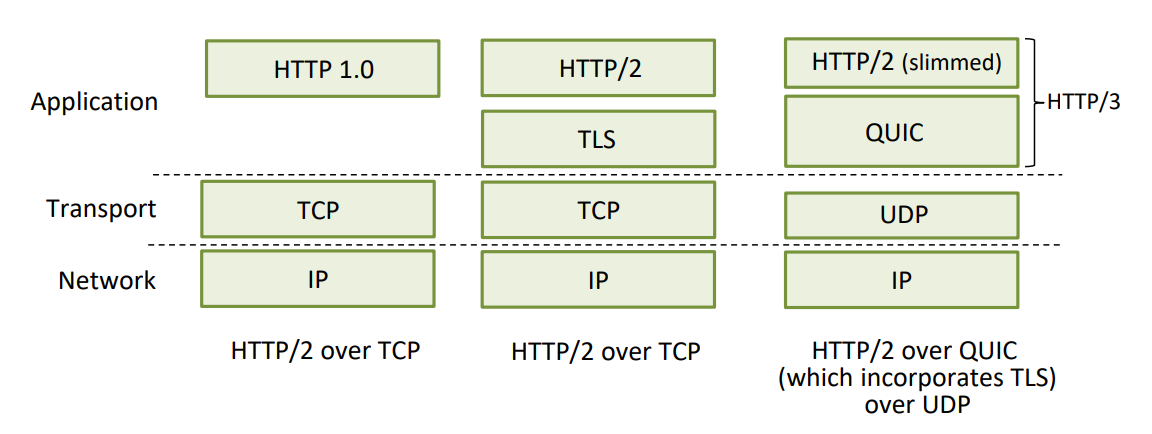
- HTTP/3: HTTP/2의 슬림 버전과 QUIC을 결합한 최신 프로토콜
TLS: 1.3 cipher suite(암호 모음)
암호 모음(Cipher Suite)
- 암호 모음은 키 생성, 암호화, 메시지 인증 코드(MAC), 디지털 서명에 사용될 수 있는 알고리즘 집합을 의미한다.
TLS 1.3
- 도입 연도: 2018년
- 특징: TLS 1.2(2008년)보다 제한된 암호 모음 선택을 제공한다.
- 선택지: TLS 1.2는 37가지 선택지를 제공하는 반면, TLS 1.3은 5가지 선택지로 제한된다.
- 키 교환 방식: Diffie-Hellman(DH) 방식만을 요구하며, DH나 RSA 방식을 사용하는 TLS 1.2와는 차이가 있다.
- 암호화 및 인증 알고리즘: 데이터에 대해 일련의 암호화 및 인증 대신 결합된 암호화 및 인증 알고리즘("인증된 암호화")을 사용한다.
- 이 중 4가지 알고리즘은 AES 기반이다.
- HMAC: SHA(256 또는 284) 암호 해시 함수를 사용한다.
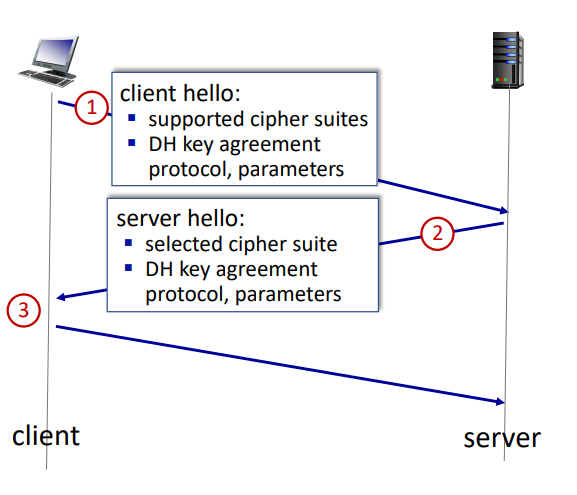
TLS 1.3 handshake: 1 RTT
- Client Hello
- 역할: 클라이언트가 서버와 통신을 시작하며, 자신이 지원하는 암호 모음(Cipher Suites)과 Diffie-Hellman(DH) 키 합의 프로토콜 및 매개변수를 서버에 알린다.
- 내용
- 클라이언트가 지원하는 암호 모음(Cipher Suites)
- DH 키 합의 프로토콜 및 매개변수
- Server Hello
- 역할: 서버는 클라이언트의 요청에 응답하며, 선택된 암호 모음, DH 키 합의 프로토콜 및 매개변수를 클라이언트에게 전달한다. 또한, 서버 서명 인증서를 클라이언트에게 제공한다.
- 내용:
- 서버가 선택한 암호 모음(Cipher Suite)
- DH 키 합의 프로토콜 및 매개변수
- 서버 서명 인증서
- Client Verification
- 역할: 클라이언트는 서버의 인증서를 확인하고, 이를 바탕으로 키를 생성한다. 이 단계가 완료되면 클라이언트는 어플리케이션 요청을 보낼 준비가 된다.(e.g. HTTPS GET 요청)
- 내용
- 서버 인증서 확인
- 키 생성
- 어플리케이션 요청 준비 완료
TLS 1.3 handshake: 0 RTT
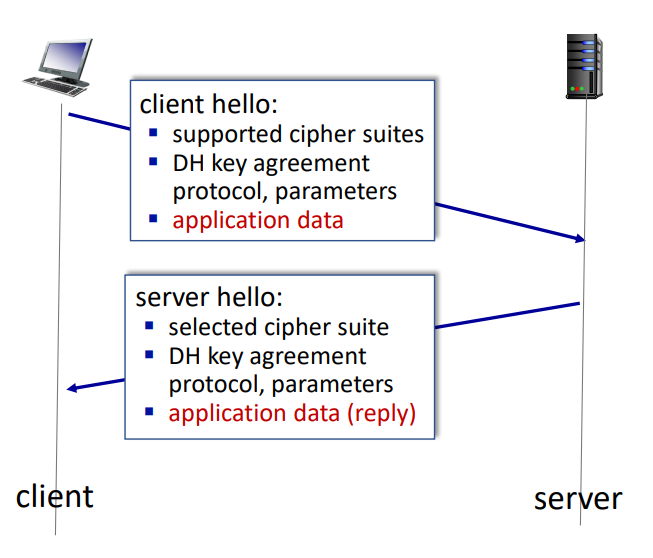
TLS 1.3의 0 RTT 핸드셰이크는 클라이언트와 서버 간의 보안 연결을 이전보다 더 빠르게 설정할 수 있도록 설계된 절차이다. 이는 초기 핸드셰이크 단계에서 이미 어플리케이션 데이터를 전송할 수 있게 해준다.
- 클라이언트 헬로(Client Hello)
- 역할: 클라이언트는 서버와의 연결을 재개하고, 지원하는 암호 모음(Cipher Suites), Diffie-Hellman(DH) 키 합의 프로토콜 및 매개변수를 서버에 알린다. 또한 초기 헬로 메시지에 암호화된 애플리케이션 데이터를 포함시킨다.
- 내용
- 클라이언트가 지원하는 암호 모음(Cipher Suites)
- DH 키 합의 프로토콜 및 매개변수
- 어플리케이션 데이터(암호화됨)
- 서버 헬로(Server Hello)
- 역할: 서버는 클라이언트의 요청에 응답하며, 선택된 암호 모음, DH 키 합의 프로토콜 및 매개변수를 클라이언트에게 전달한다. 또한, 초기 헬로 메시지에 암호화된 어플리케이션 데이터에 대한 응답을 포함시킨다.
- 내용
- 서버가 선택한 암호 모음(Cipher Suite)
- DH 키 합의 프로토콜 및 매개변수
- 어플리케이션 데이터(응답, 암호화됨)
IP Sec
IP Sec는 사용자 트래픽과 제어 트래픽(BGP, DNS 메시지 등) 모두에 대해 데이터그램 수준의 암호화, 인증, 무결성을 제공하는 보안 프로토콜이다. IP Sec는 두 가지 모드로 동작한다. 전송 모드(Transport Mode) 와 터널 모드(Tunnel Mode) 이다.
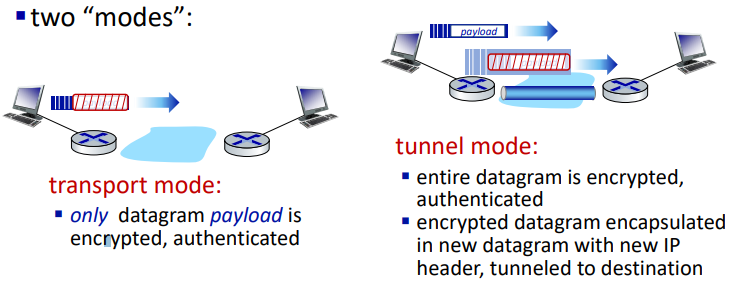
- 전송 모드(Transport Mode)
- 설명: 전송 모드에서는 데이터그램의 페이로드(Payload)만이 암호화되고 인증된다.
- 특징
- 암호화와 인증이 데이터그램의 내용에만 적용된다.
- IP 헤더는 암호화되지 않는다.
- 호스트 간 직접 통신에 주로 사용된다.
- 그림 설명: 전송 모드에서는 데이터그램의 페이로드 부분이 빨간색으로 표시되어 암호화 및 인증됨을 나타내고, 페이로드를 제외한 나머지 부분은 암호화되지 않은 상태로 유지된다.
- 터널 모드(tunnel mode)
- 설명: 터널 모드에서는 데이터그램 전체가 암호화되고 인증된다.
- 특징
- 원본 데이터그램이 전체적으로 암호화되고, 새로운 IP 헤더를 추가하여 새로운 데이터그램으로 캡슐화된다.
- VPN(Virtual Private Network)에서 흔히 사용된다.
- 데이터그램이 게이트웨이 간에 터널링되어 전송된다.
- 그림 설명: 터널 모드에서는 전체 데이터그램이 암호화되어 파란색으로 표시되고, 새로운 IP 헤더가 추가되어 목적지까지 터널링됨을 나타낸다.
Two IPsec protocols
IPSec(Internet Protocol Security)에는 두 가지 주요 프로토콜이 있다. Authentication Header(AH) 프로토콜과 Encapsulation Security Protocol(ESP)
- Authentication Header(AH) 프로토콜
- 기능: AH 프로토콜은 출처 인증과 데이터 무결성을 제공하지만, 기밀성(암호화)은 제공하지 않는다.
- 특징:
- 출처 인증: 데이터그램이 인증된 출처에서 온 것임을 보장한다.
- 데이터 무결성: 데이터그램이 전송 중에 변경되지 않았음을 보장한다.
- 기밀성 없음: 데이터 자체는 암호화되지 않으므로, 중간에서 데이터를 볼 수 있다.
- Encapsulation Security Protocol(ESP)
- 기능: ESP는 출처 인증, 데이터 무결성 및 기밀성을 제공한다.
- 특징:
- 출처 인증: 데이터그램이 인증된 출처에서 온 것임을 보장한다.
- 데이터 무결성: 데이터그램이 전송 중에 변경되지 않았음을 보장한다.
- 기밀성: 데이터가 암호화되어 중간에서 데이터를 볼 수 없다.
- 더 널리 사용됨: AH보다 ESP가 더 널리 사용된다. 이는 ESP가 기밀성까지 제공하기 때문이다.
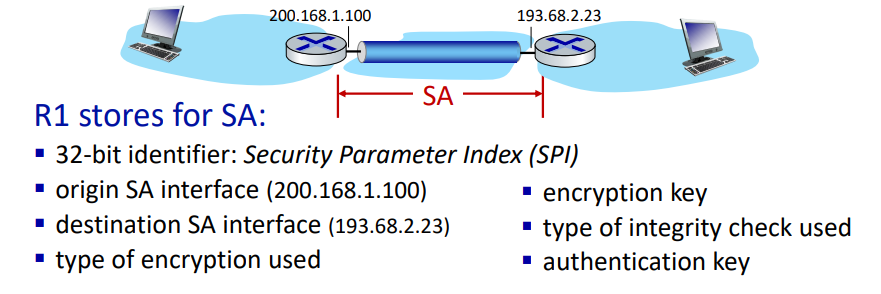
Security Associatoins(SAs)
Security Association(SA) 는 IPsec 프로토콜에서 데이터 전송 전에 보안 매개변수를 설정하기 위해 사용된다. 이는 보안된 통신을 위해 필요하며, 방향성이 있다. 즉, 송신자에서 수신자로의 데이터 전송에 대해 각각의 SA가 설정된다.
보안 연결 설정
- 데이터 전송 전에 송신자와 수신자 간에 Security Association(SA) 가 설정된다.
- 이는 방향성이 있으므로, 송신에서 수신으로, 수신에서 송신으로 각각 SA가 필요하다.
상태 정보 유지
송신자와 수신자는 SA에 대한 상태 정보를 유지한다.
이는 TCP 연결에서 상태 정보를 유지하는 것과 유사하다.
IP는 비연결성 프로토콜이지만, IPsec은 연결 지향적이다.
IPsec Datagram
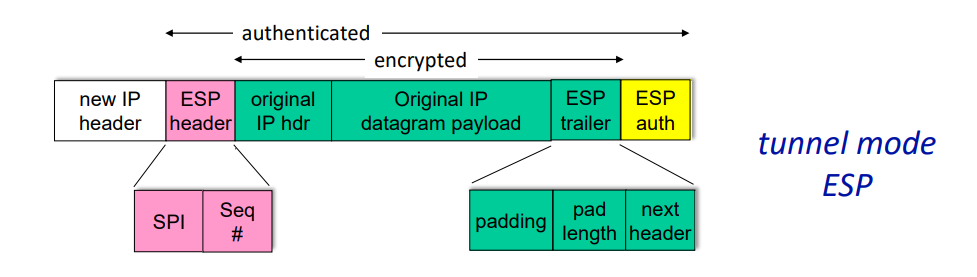
- 새 IP 헤더(New IP Header)
- 터널 모드에서는 원래 IP 헤더와 페이로드를 암호화하기 위해 새로운 IP 헤더가 추가된다.
- ESP 헤더(ESP Header)
- SPI(Security Parameters Index): 수신 측에서 수신한 데이터가 어떤 SA에 해당하는 식별합니다.
- Sequence Number: 재전송 공격을 방지하기 위해 사용된다.
- 원래 IP 헤더(Original IP Header) 및 원래 IP 데이터그램 페이로드(Original IP Datagram Payload)
- 원래의 IP 헤더와 데이터 페이로드는 ESP 헤더 뒤에 위치하며, 터널 모드에서는 암호화된다.
- ESP 트레일러(ESP Trailer)
- 패딩(Padding): 블록 암호화 방식에서 데이터 길이를 블록 크기의 배수로 맞추기 위해 추가한다.
- 패딩 길이(Pad Length): 패딩의 길이를 나타낸다.
- 다음 헤더(Next Header): 원래 데이터그램의 다음 포로토콜을 나타낸다.
- ESP 인증(ESP Authentication)
- 인증 필드에는 MAC(Message Authentication Code)이 포함되어 있으며, 공유된 비밀키로 생성된다.
- 이 필드는 데이터그램의 무결성을 확인하고 인증하는 데 사용된다.
ESP tunnel mode: actions
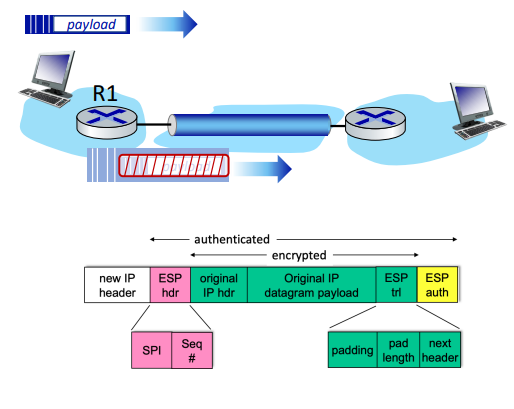
ESP(Encapsulating Security Payload) 터널 모드에서는 네트워크 트래픽을 암호화하고 인증하고 안전하게 전송한다.
동작 과정
ESP 트레일러 추가
- 원래 데이터그램에 ESP 트레일러를 추가한다. 이 트레일러는 패딩(padding) 및 패딩 길이(pad length)와 다음 헤더(next header) 정보를 포함합니다.
암호화
- SA(Security Association)에서 지정된 알고리즘과 키를 사용하여, ESP 트레일러가 추가된 데이터그램을 암호화한다. 이때 원래 IP 헤더와 페이로드가 포함된 데이터 전체가 암호화된다
ESP 헤더 추가
- 암호화된 데이터 앞에 ESP 헤더를 추가합니다. 이 헤더에는 SPI(Security Parameters Index)와 시퀀스 번호(sequence number)가 포함됩니다.
MAC 생성
- SA에서 지정된 알고리즘과 키를 사용하여 인증 MAC(Message Authentication Code)를 생성한다. 이는 데이터의 무결성을 검증하는 데 사용된다.
MAC 추가
- 생성된 MAC을 페이로드에 추가한다. 이로써 인증된 페이로드가 완성된다.
새로 IP 헤더 생성
- 새로운 IP 헤더를 생성하고, 새로운 IP 헤더 필드를 추가하여 터널 끝점(tunnel endpoint)으로 주소를 설정한다. 이 새로운 IP 헤더는 암호화된 데이터를 터널을 통해 전송하는 데 사용됩니다.
IPsec sequence numbers
IPsec(Internet Protocol Security) 시퀀스 번호는 보안 연관(Security Assoication, SA) 내에서 데이터그램의 순서를 관리하는 데 사용된다. 이를 통해 데이터그램의 재생 공격을 방지하고 데이터의 무결성을 유지할 수 있다.
동작 방식
새 SA에서 시퀀스 번호 초기화
- 새로운 보안 연관(SA)이 설정될 때 송신자는 시퀀스 번호를 0으로 초기화한다.
데이터그램 전송 시 시퀀스 번호 증가
- 송신자는 데이터그램을 보낼 때마다 시퀀스 번호 카운터를 증가시킨다.
- 증가된 시퀀스 번호는 데이터그램의 시퀀스 번호 필드에 삽입된다.
목표
- 재생 공격 방지
- 공격자가 데이터그램을 가로채어 재전송하는 것을 막기 위해 사용된다.
- 중복된, 인증된 IP 패킷이 수신될 경우 서비스 장애를 유발할 수 있으므로 이를 방지한다.
방법
- 중복 체크
- 수신자는 중복된 데이터그램을 검사한다.
- 수신된 모든 패킷을 추적하지 않고, 대신에 윈도우(window) 방식을 사용하여 시퀀스 번호를 관리한다.
IPsec Security Databases
Security Policy Database(SPD)
- 목적
- 특정 데이터그램에 대해 IPsec을 사용할지 여부를 결정하는 정책을 저장한다.
- 내용
- 보안 정책이 저장된다.
- 데이터그램을 처리할 때 어떤 보안 연결(SA)을 사용할지 결정한다.
- 기능
- 소스와 목적지 IP 주소 및 프로토콜 번호와 같은 기준을 사용하여 적절한 SA를 선택한다.
- 역할
- SPD는 무엇을 해야 하는지를 규정한다.
**Security Assoication Database(SAD)** - 목적 - 보안 연결(SA)의 상태 정보를 저장한다. - 내용 - 보안 연결(SA)의 상태 정보가 저장된다 - 기능 - IPsec 데이터그램을 전송할 때 SAD에 접근하여 데이터그램을 어떻게 처리할지 결정한다. - IPsec 데이터그램이 수신될 때, 수신자는 SPI(Security Parameter Index)를 검사하여 SAD를 참조하고 데이터그램을 처리한다. - 역할 - SAD는 어떻게 해야 하는지를 규정한다.
요약
- SPD: 어떤 행동을 해야 하는지(what to do)에 대한 정책을 정의한다.
- SAD: 그 행동을 어떻게 수행할지(How to do it)에 대한 세부 정보를 제공한다.
Summary: IPsec services
IPsec의 보안 서비스를 요약하고 있다. Trudy라는 공격자가 R1과 R2 사이에 의치해 있으며, 암호화 키를 모르는 상황을 가정하자. Trudy가 할 수 있는 몇 가지 공격 시나리오를 설명하고, IPsec이 어떻게 이러한 공격을 방지할 수 있는지에 대해 설명한다.
- Will Trudy be able to see original contents of datagram? How about source, dest IP address, transport protocol, application port?
- IPsec의 역할: IPsec은 데이터그램의 원래 내용을 암호화하여 Trudy가 내용을 읽지 못하게 한다. ESP(Encapsulation Security Payload)를 사용하면 데이터그램의 페이로드 뿐만 아니라 IP 헤더도 암호화할 수 있다.
- 효과: Trudy는 데이터그램의 내용을 볼 수 없고, 소스 및 목적지 IP 주소, 전송 프로토콜, 어플리케이션 포트도 알 수 없다.
- Flip bits without detection?
- IPsec의 역할: IPsec은 데이터그램의 무결성을 확인하기 위해 MAC(Message Authentication Code)를 사용합니다. ESP와 AH(Authentication Header)는 데이터그램이 전송 중에 수정되지 않았음을 보장한다.
- 효과: Trudy가 데이터그램의 비트를 변경하면 수신 측에서 무결성 검사가 실패하게 되어, 변경된 데이터그램이 탐지된다.
- Masquerade as R1 using R1’s IP address?
- IPsec의 역할: IPsec은 인증을 통해 발신자의 신원을 확인한다. SA(Security Association)는 신뢰할 수 있는 엔티티 간에만 설정되므로, Trudy는 R1로 가장할 수 없다.
- 효과: Trudy가 R1의 IP 주소를 사용하여 자신을 R1로 가장할 수 없다
- Replay a datagram?
- IPsec의 역할: IPsec은 재전송 공격을 방지하기 위해 시퀀스 번호를 사용한다. 수신자는 데이터그램의 시퀀스 번호를 확인하여 중복된 데이터그램을 거부한다.
- 효과: Trudy가 이전에 캡처한 데이터그램을 재전송하려고 해도 수신자는 이를 탐지하고 거부한다.
IKE: Internt Key Exchange
Internet Key Exchange
- 이 슬라이드는 IPsec의 보안 연관(Security Association, SA)을 수동으로 설정하는 것과 자동화된 방법인 IKE(Internet Key Exchange)를 사용하는 것의 차이점을 설명한다.
문제점: 수동 키 설정의 비효율성
- 수동 키 설정(manual keying)은 많은 수의 엔드포인트가 있는 VPN에서 비효율적이다. 각 엔드포인트마다 이러한 설정을 수동으로 해야하는데, 이는 시간과 노력이 많이 드는 작업이다.
해결책: IPsec IKE(Internet Key Exchange)
- IKE(Internet Key Exchange)는 이러한 수동 설정의 문제를 해결하기 위해 사용된다. IKE는 자동으로 IPsec의 SA를 설정하고 관리하는 프로토콜이다.
- 주요기능
- 자동으로 키 교환
- 보안 연관 설정 자동화
- 키 관리 및 재협상
IKE를 사용하면 수 백개의 엔드포인트가 있는 큰 규모의 VPN에서도 효율적으로 SA를 관리할 수 있다. 이는 보안과 운영 효율성을 동시에 개선할 수 있는 중요한 방법이다.
IKE: PSK and PKI
IPsec에서 인증을 수행하기 위한 두 가지 주요 방법인 PSK(Pre-Shared Key)와 PKI(Public Key Infrastructure)를 설명한다.
Authentication(Prove Who You Are)
- PSK(Pre-Share Secret): 사전에 공유된 비밀을 사용하여 인증한다.
- PKI(Public/Private Keys and Certifivates): 공개 키와 개인 키, 그리고 인증서를 사용하여 인증한다.
PSK(Pre-Shared Secret)
- 초기 상태: 양쪽 모두 사전에 공유된 비밀을 알고 있다.
- 과정:
- IKE를 사용하여 서로를 인증한다.
- IPsec SA를 생성한다. 여기에는 암호화 키와 인증 키가 포함된다
- 각 방향에 대해 하나의 SA를 생성한다.
PKI(Public/Private Keys and Certificates)
- 초기 상태: 양쪽 모두 공개/개인 키 쌍과 인증서를 가지고 있다.
- 과정:
- IKE를 실행하여 서로를 인증한다.
- IPsec SA를 얻는다. 각 방향에 대해 하나의 SA를 생성한다.
- SSL의 핸드셰이크와 유사하다.
요약
- PSK는 사전에 공유된 비밀을 사용하여 간단하게 설정할 수 있지만, 대규모 네트워크에서는 관리가 어려울 수 있다.
- PKI는 공개 키와 인증서를 사용하여 더 높은 보안을 제공하며, 대규모 네트워크에서도 효율적으로 관리할 수 있다.
IKE phases
phase 1: Establish Bi-Directional IKE SA
- 목적: 양방향 IKE SA(Secure Association)를 설정한다.
- 주의: IKE SA는 IPsec SA와 다르다.
- 별칭: ISAKMP(Internet Security Association and Key Management Protocol) 보안 연결
phase 2: Use ISAKMP to Securely Negotiate IPsec Pair of SAs
- 목적: ISAKMP를 사용하여 IPsec SA 쌍을 안전하게 협상한다.
Phase 1 Modes
Aggressive Mode
- 특징: 더 적은 메시지를 사용하여 빠르게 IKE SA를 설정한다.
Main Mode
- 특징: 신원 보호를 제공하고 더 유연하다.
- 장점: 공격으로부터 더 안전하게 신원 정보를 보호할 수 있다.
IPsec summary
Key Exchange(IKE)
- 목적: 알고리즘, 비밀 키, SPI(Security Parameter Index) 번호를 교환한다.
- 작동 방식: IKE 메시지 교환을 통해 필요한 정보를 안정하게 교환한다.
Protocols
- AH(Authentication Header)
- 기능: 무결성과 출처 인증을 제공한다.
- ESP(Encapsulating Security Payload)
- 기능: AH와 함께 사용할 경우 암호화 기능을 추가로 제공한다
- 요약: AH는 무결성과 인증을, ESP는 추가로 암호화를 제공한다.
- IPsec Peers
- 유형:
- 두 개의 엔드 시스템
- 두 개의 라우터 또는 방화벽
- 라우터/방화벽과 하나의 엔드 시스템
- 설명: IPsec 피어는 위와 같이 다양한 조합이 가능하다.
- 유형:
802.11: authentication, encryption
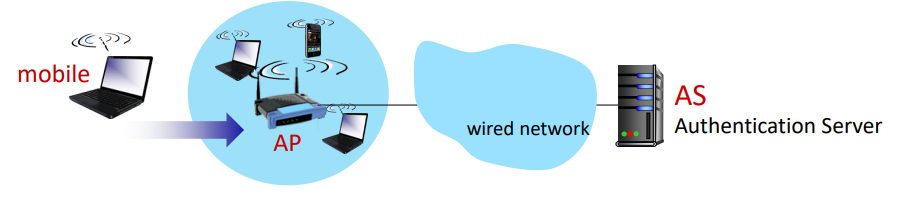
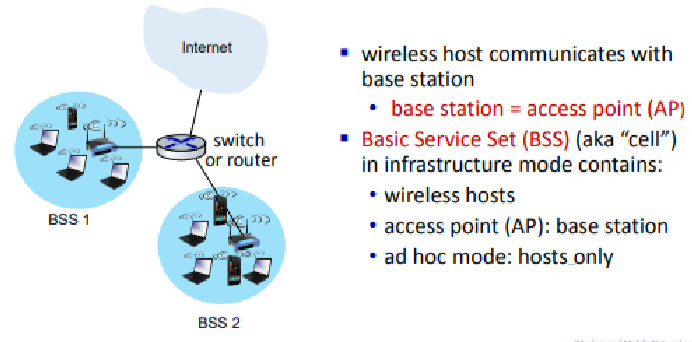
Process Overview
- Association with Access Point(AP)
- 목적: 무선 링크를 통해 AP와 통신을 설정하는 것
- 설명: 이동 장치(모바일 디바이스)는 무선 네트워크에 연결되기 위해 먼저 근처의 AP와 연결을 설정해야 한다.
- Authentication to Network
- 목적: 네트워크에 인증을 받는 것
- 설명: AP와 연결된 후, 이동 장치는 네트워크에 인증을 받아야 한다. 이는 네트워크 접근을 제어하고 보안을 유지하기 위함이다.
- Componenets
- Mobile: 무선 네트워크에 연결하려는 이동 장치(e.g. 노트북, 스마트폰)
- AP(Access Point): 무선 네트워크의 중앙 장치로, 이동 장치가 연결될 수 있는 지점이다.
- AS(Authentication Server): 네트워크의 인증 서버로, 이동 장치의 인증을 처리한다.
- Wired Network: AP가 연결된 유선 네트워크이다.
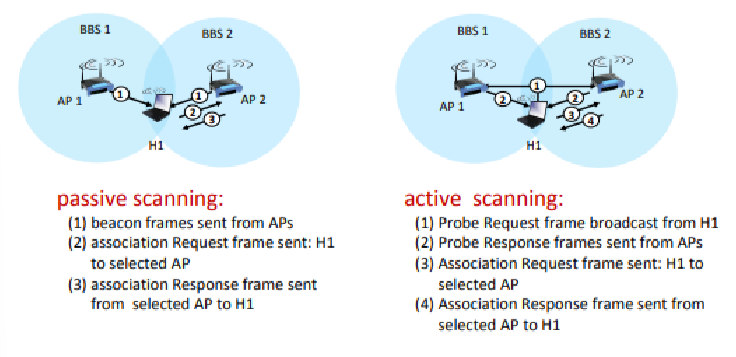
802.11 Authentication and Encrpytion - Discover of Security Capabilities
이 슬라이드는 802.11 프로토콜에서 인증 및 암호화 기능을 발견하는 과정을 설명한다.
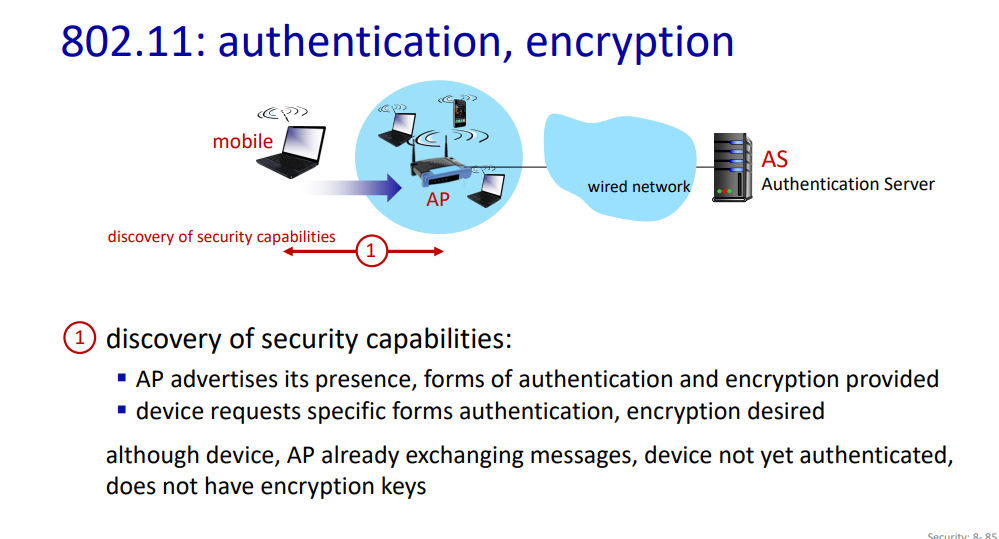
단계 1: 보안 기능 발견
- AP 광고(Advertise)
- AP(Access Point)는 자신의 존재와 지원하는 인증 및 암호화 형태를 광고한다.
- 이동 장치(모바일 디바이스)는 이 광고를 수신하고 특정 인증 및 암호화 형태로를 요청한다.
- 장치 요청(Request)
- 이동 장치는 특정한 형태의 인증 및 원하는 암호화를 요청한다.
- 이 과정은 장치가 아직 인증되고 않았고 암호화 키를 갖고 있지 않지만, 이미 AP와 메시지를 교환하고 있다는 것을 의미한다.
802.11: authentication, encryption
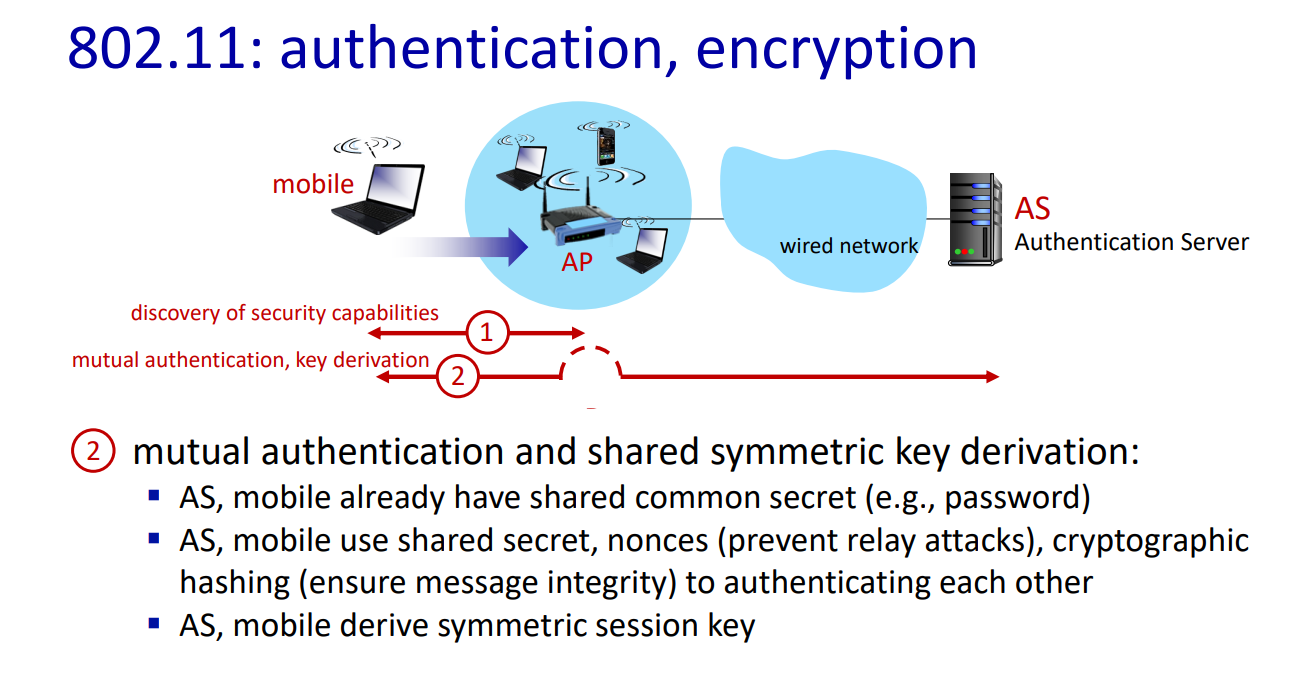
단계 2: 상호 인증 및 공유 대칭 키 파생
- AS 및 모바일 장치 간의 공유 비밀
- AS(Authentication Server)와 모바일 장치는 이미 공유된 공통 비밀(e.g. 비밀번호)을 가지고 있다.
- 공유 비밀, 논스 및 암호화 해시를 사용한 인증
- AS와 모바일 장치는 공유된 비밀과 넌스(Nonces)를 사용하여 인증을 수행한다.
- 넌스는 릴레이 공격을 방지하기 위해 사용되며, 암호화 해시는 메시지 무결성을 보장한다.
- 대칭 세션 키 파생
- AS와 모바일 장치는 공유된 비밀을 사용하여 대칭 세션 키를 파생한다
- 이 대칭 키는 이후의 통신에서 사용된다.
802.11: WPA3 handshake

WPA3 프로토콜에서의 핸드 셰이크 과정을 설명한다. WPA3는 Wi-Fi 네트워크의 보안을 강화하기 위한 최신 프로토콜로, 특히 강화된 인증 및 암호화 메커니즘을 사용한다.
주요 개념
- Nonce: 한 번만 사용되는 임의의 숫자로, 재사용 공격을 방지
- HMAC(Hash-based Message Authentication Code): 메시지의 무결성과 인증을 확인하는 해시 함수 기반의 코드
- 대칭 키 암호화: 송신자와 수신자가 동일한 키를 사용하여 데이터를 암호화하고 복호화하는 방식
단계별 설명
- Initial Setup(초기 설정)
- 모바일 장치와 인증 서버(AS)는 초기 공유 비밀을 이미 가지고 있다.
- 이를 바탕으로 세션 키 KM-AP를 파생한다.
- Step a
- AS 생성 논스 NonceAS를 생성한다.
- 이 논스를 모바일 장치로 전송한다.
- Step b
- 모바일 장치 수신 NonceAS
- 모바일 장치는 인증 서버로부터 NonceAS를 수신한다.
- 모바일 장치 생성 NonceM
- 모바일 장치는 자체적으로 넌스 NonceM를 생성한다.
- 대칭 공유 세션 키 KM-AP 생성
- 모바일 장치는 NonceAS, NonceM 그리고 초기 공유 비밀을 사용하여 대칭 공유 세션 키 KM-AP를 생성한다.
- 넌스와 HMAC 전송
- 모바일 장치는 NonceM와 NonceAS 및 초기 공유 비밀을 사용하여 생성한 HMAC 값을 인증 서버로 전송한다.
- 모바일 장치 수신 NonceAS
- Step c:
- AS 파생 대칭 공유 세션 키 KM-AP
- 인증 서버는 모바일 장치로부터 NonceM와 HMAC 값을 수신한다.
- NonceAS, NonceM, 그리고 초기 공유 비밀을 사용하여 대칭 공유 세션 키 KM-AP를 파생한다.
- AS 파생 대칭 공유 세션 키 KM-AP
- Discovery of Security Capabilities (보안 기능 발견):
- AP가 자신의 존재와 제공하는 인증 및 암호화 형태를 광고한다.
- AP는 자신이 지원하는 인증 및 암호화 메커니즘을 브로드캐스트한다.
- 장치가 원하는 인증 및 암호화 형태를 요청한다.
- 모바일 장치는 네트워크에 연결하기 위해 AP에게 특정 인증 및 암호화 방법을 요청한다.
- 이 시점에서는 장치와 AP가 이미 메시지를 교환하고 있지만, 아직 인증되지 않았고 암호화 키도 없는 상태이다.
- AP가 자신의 존재와 제공하는 인증 및 암호화 형태를 광고한다.
- Mutual Authentication, Key Derivation (상호 인증, 키 파생):
- AS(인정 서버)와 모바일 장치가 초기 공유 비밀(e.g. password)을 이미 가지고 있다.
- AS와 모바일 장치는 공유 비밀과 넌스(Nonce)를 사용하여 서로를 인증하고 세션 키를 파생한다.
- AS와 모바일 장치는 공유 비밀, 논스, 그리고 암호화 해싱을 사용하여 서로를 인증합니다.
- 이 과정에서 재전송 공격을 방지하기 위해 논스를 사용한다.
- Shared Symmetric Key Distribution(공유 대칭 키 배포)
- 모바일 장치와 AS에서 동일한 세션 키가 파생된다.
- AS와 모바일 장치는 상호 인증 과정에서 파생된 대칭 세션 키를 사용한다.
- AS는 공유 대칭 세션 키를 AP에게 전달한다.
- AP는 AS로부터 전달받은 대칭 세션 키를 사용하여 모바일 장치와의 통신을 암호화한다.
- 모바일 장치와 AS에서 동일한 세션 키가 파생된다.
802.11: Authentication, Encryption
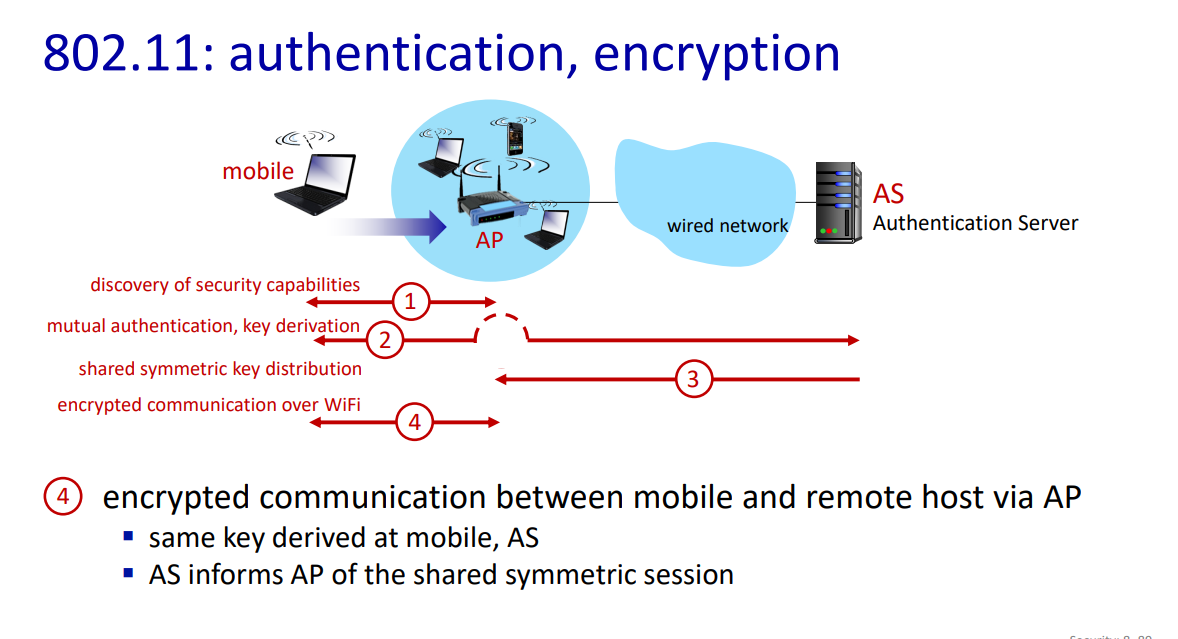
Discovery of Security Capabilities (보안 기능 발견):
- AP가 자신의 존재와 제공하는 인증 및 암호화 형태를 광고합니다.
- AP는 자신이 지원하는 인증 및 암호화 메커니즘을 브로드캐스트합니다.
- 장치가 원하는 인증 및 암호화 형태를 요청합니다.
- 모바일 장치는 네트워크에 연결하기 위해 AP에게 특정 인증 및 암호화 방법을 요청합니다.
- 이 시점에서는 장치와 AP가 이미 메시지를 교환하고 있지만, 아직 인증되지 않았고 암호화 키도 없는 상태입니다.
- AP가 자신의 존재와 제공하는 인증 및 암호화 형태를 광고합니다.
Mutual Authentication, Key Derivation (상호 인증, 키 파생):
- AS(인증 서버)와 모바일 장치가 초기 공유 비밀(예: 패스워드)을 이미 가지고 있습니다.
- AS와 모바일 장치는 공유 비밀과 논스(Nonce)를 사용하여 서로를 인증하고 세션 키를 파생합니다.
- AS와 모바일 장치는 공유 비밀, 논스, 그리고 암호화 해싱을 사용하여 서로를 인증합니다.
- 이 과정에서 재전송 공격을 방지하기 위해 논스를 사용합니다.
Shared Symmetric Key Distribution (공유 대칭 키 배포):
- 모바일 장치와 AS에서 동일한 세션 키가 파생됩니다.
- AS와 모바일 장치는 상호 인증 과정에서 파생된 대칭 세션 키를 사용합니다.
- AS는 공유 대칭 세션 키를 AP에게 전달합니다.
- AP는 AS로부터 전달받은 대칭 세션 키를 사용하여 모바일 장치와의 통신을 암호화합니다.
- 모바일 장치와 AS에서 동일한 세션 키가 파생됩니다.
Encrypted Communication over WiFi (WiFi를 통한 암호화된 통신):
- 동일한 키가 모바일 장치와 AS에서 파생됩니다.
- AS는 AP에게 공유 대칭 세션을 알립니다.
- 모바일 장치와 AP 간의 통신은 암호화된 상태로 이루어집니다.
- 이를 통해 모바일 장치와 AP, 그리고 네트워크 전체의 통신이 안전하게 보호됩니다.
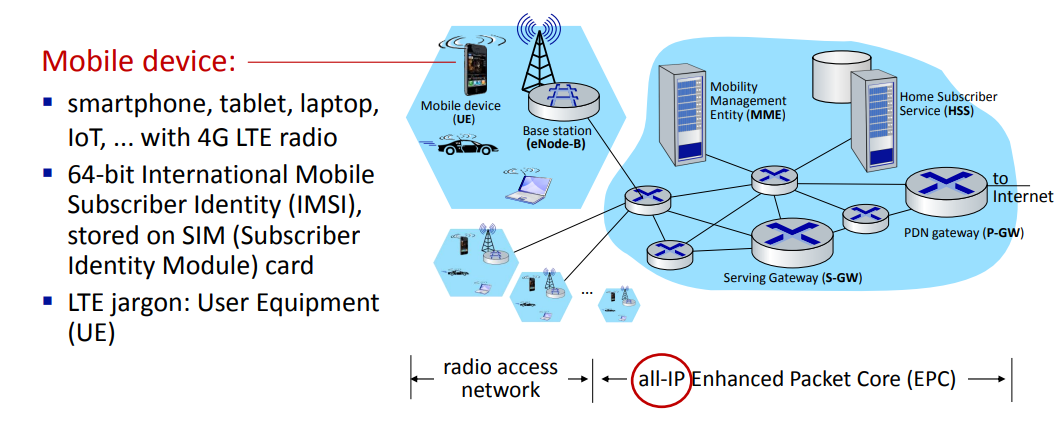
Authentication, encryption in 4G LTE
주요 요소
- 모바일 장치: 사용자 장치로, 세션 키 KBS-M과 KHSS-M을 사용하여 통신을 암호화한다.
- 기지국(Base Station, BS): 모바일 장치와 연결을 관리하며, 파생 세션 키 KBS-M을 사용하여 통신을 암호화한다.
- 이동성 관리 엔티티(Mobility Management Entity, MME): 네트워크 내에서 모바일 장치의 이동성을 관리한다.
- 홈 가입자 서비스(Home Subscriber Service, HSS): 홈 네트워크에 위치하며, 인증 및 구독 정보를 관리한다. 궁극적인 인증 기관이다
a단계
- Attach 요청
- 모바일 장치는 "attach" 요청 메시지를 보낸다. 이 메시지에는 다음이 포함된다.
- IMSI(International Mobile Subscriber Identity): 모바일 장치의 고유 식별자
- 방문 네트워크 정보: 모바일 장치가 현재 연결하려고 하는 네트워크에 대한 정보
- 이 attach 메시지는 먼저 기지국(BS)로 전송된다.
- 모바일 장치는 "attach" 요청 메시지를 보낸다. 이 메시지에는 다음이 포함된다.
- 방문 네트워크로의 전송
- 기지국은 attach 메시지를 방문 네트워크의 MME(Mobility Management Entity)로 전달한다.
- MME는 이 메시지를 홈 네트워크의 HSS(Home Subscriber Service)로 다시 전달한다.
- IMSI 확인
- HHS IMSI를 사용하여 모바일 장치의 홈 네트워크를 식별한다. 이 정보를 통해 홈 네트워크는 인증을 진행할 수 있다.
b단계: HSS가 인증 토큰(auth_token)과 예상되는 인증 응답 토큰(xres_HSS)을 생성하는 과정을 설명한다.
- 사전 공유 비밀 키 사용
- HSS는 사전에 공유된 비밀 키 KHSS-M을 사용하여 인증 토큰(auth_token)과 예상되는 인증 응답 토큰(xres_HSS)을 생성한다.
- 인증 토큰(auth_token) 생성
- auth_token은 KHSS-M을 사용하여 HSS에 의해 암호화된 정보를 포함한다.
- 이 토큰을 통해 모바일 장치는 토큰을 생성한 주체가 공유된 비밀 키를 알고 있다는 사실을 확인할 수 있다.
- HSS가 auth_token과 xres_HSS 생성
- auth_token에는 암호화된 정보가 포함되어 있으며, 이 정보는 모바일 장치가 네트워크를 인증했음을 나타낸다.
- xres_HSS는 HSS가 나중에 사용할 수 있도록 보관한다.
- AUTH_RESP 메시지 전송
- HSS는 auth_token과 xres_HSS 및 기타 필요한 키를 포함한 AUTH_RESP 메시지를 생성하여 MME에 전송한다.
- 이 메시지는 다시 방문 네트워크를 통해 모바일 장치에 전달된다.
- 모바일 장치 인증
- 모바일 장치는 AUTH_RESP 메시지의 auth_token을 검증하여 네트워크를 인증한다.
- auth_token을 올바르게 생성한 주체는 KHSS-M를 알고 있어야 하므로, 모바일 장치는 네트워크가 신뢰할 수 있는 네트워크임을 확인할 수 있다.
c단계: 모바일 장치의 인증 응답
- 비밀 키를 사용한 계산
- 모바일 장치는 자신의 비밀 키를 사용하여 HSS와 동일한 암호화 계산을 수행하여 응답 토큰 resM을 생성한다.
- 이 과정은 HSS가 xres_HSS를 계산한 방법과 동일한 방식으로 수행된다.
- 응답 토큰 생성
- 모바일 장치는 HSS가 생성한 xres_HSS와 동일한 방법으로 응답토큰 resM을 생성한다.
- 이를 통해 모바일 장치는 자신이 HSS와 동일한 비밀 키를 공유하고 있음을 증명할 수 있다.
- MME로 전송
- 생성된 응답 토큰resM을 MME에 전송한다.
- 이 응답은 모바일 장치가 네트워크에 인증되었음을 나태난다
- 인증 확인
- MME는 모바일 장치로부터 받은 resM과 HSS로부터 받은 xres_HSS를 비교한다.
- 두 값이 일치하면, 모바일 장치는 성공적으로 인증된 것으로 간주된다.
d 단계: 4G LTE에서의 인증 및 암호화
- MME와 HSS의 응답 비교
- MME는 모바일 장치로부터 받은 resM값을 HSS에서 계산한 xresHSS값과 비교한다.
- 두 값이 일치하면, 모바일 장치는 성공적으로 인증된 것으로 간주된다.
- 인증의 이유
- 왜 이 방법으로 인증이 이루어지는가?
- resM와 xresHSS가 일치하면, 이는 모바일 장치와 HSS가 동일한 비밀 키를 공유하고 있음을 의미한다.
- 이는 모바일 장치가 네트워크에 올바르게 인증되었음을 보장한다.
- 왜 이 방법으로 인증이 이루어지는가?
- BS에게 인증 상태 알림
- MME는 기지국(BS)에게 모바일 장치가 인증되었음을 알린다.
- 이를 통해 BS는 모바일 장치와의 통신을 시작할 수 있다.
- 암호화 키 생성
- MME는 BS와 모바일 장치 간의 통신을 위해 필요한 암호화 키를 생성한다.
- 이러한 키는 모바일 장치와 BS 간의 데이터를 안전하게 암호화하고 보호하는 데 사용된다.
e 단계: 4G LTE에서의 인증 및 암호화
모바일 장치와 기지국이 4G 무선 채널을 통해 데이터를 암호화하고 제어 프레임을 보호하기 위한 키를 결정하는 과정을 설명한다.
- 키 결정
- 모바일 장치와 기지국(BS)은 4G 무선 채널을 통해 데이터를 암호화하기 위한 키를 결정한다.
- 이 과정을 상호 간의 안전한 통신을 보장한다.
- AES 암호화 사용 가능
- 결정된 키는 AES(Advanced Encryption Standard)와 같은 강력한 암호화 알고리즘을 사용하여 데이터를 암호화하고 사용될 수 있다.
'학교수업 > 컴퓨터망' 카테고리의 다른 글
| Chapter7: Wireless and Mobile Networks (4) | 2024.07.14 |
|---|---|
| Chapter6: The Link Layer and LANs (0) | 2024.07.12 |
| Chapter5 Network Layer: Control Plane (0) | 2024.07.09 |
| Chapter4: Network Layer-Data Plane (0) | 2024.07.04 |
| Chapter3: Transport Layer-2 (0) | 2024.07.04 |



























































































































{kind=link}
{kind=link}