Transport Layer: overview
our goal
- transport layer의 service들의 principle을 이해하는 것
- multiplexing, demultiplexing
- reliable data transfer
- flow control
- congesion control
- internet transport layer protocol를 배우기
- UDP: 비연결 전송
- TCP: 연결지향, 신뢰성있는 전송
- TCP congestion control
Transport Layer: roadmap
- Transport-layer service
- multiplexing and demultiplexing
- connectionless trasnport : UDP
- principles of reliable data transfer
- connection-oriented trasport : TCP
- Principle of congestion control
- TCP congestion control
- Evolution of Transport-layer functionality
Transport services and protocols
- Logical Communication
- 전송 계층은 서로 다른 호스트에서 실행되는 어플리케이션 프로세스 간의 논리적 통신(logical communication)을 제공한다.
- e.g. 모바일 네트워크, 홈 네트워크, 기업 네트워크, 지역 ISP, 국가 또는 글로벌 ISP, 데이터 센터 네트워크, 컨텐츠 제공자 네트워크 등을 포함한다.
- Transport Protocol Actions in End Systems
- 송신 측(sender)
- 어플리케이션 메시지를 새그먼트(segment) 로 분할하고 이를 네트워크 계층으로 전달한다.
- 수신 측(receiver)
- segment를 재조립하여 메시지를 만들고 이를 어플리케이션 계층으로 전달한다.
- 송신 측(sender)
- Available Trasnport Protocols
- 인터넷 어플리케이션에 사용 가능한 두 가지 전송 프로토콜은 TCP와 UDP이다.
- TCP(Trasnport Control Protocol)
- 연결 지향적이고 신뢰성 있는 전송을 제공
- UDP(Transport Datagram Protocol)
- 비연결형 전송을 제공, 신뢰성은 낮음

Trasnport vs Network Layer Services and Protocols
- household 비유
- Ann의 house의 12명의 애들이 Bill의 house의 12명의 애들에게 편지를 쓰려고 한다.
- hosts = houses
- process = kids
- app message = letters in envelopes
- Ann의 house의 12명의 애들이 Bill의 house의 12명의 애들에게 편지를 쓰려고 한다.
- Network Layer: host 간의 데이터 전송을 책임진다.
- Transport Layer: process 사이의 데이터 전송을 관리하고 제어한다.
Transport Layer Actions

송신자(Sender)
- application layer의 message를 전달받음
- 송신자는 응용 계층에서 메시지를 전달 받는다.
- segment header의 field 값을 결정
- 메시지를 세그먼트로 분할할 때 세그먼트 헤더에 들어갈 값을 결정한다. 이는 각 세그먼트를 올바르게 전달하고 재조립하기 위해 필요하다.
- segment를 생성
- application meesage를 segment로 만든다. segment는 데이터와 segment 헤더로 구성된다.
- segment를 IP 계층으로 전달
- 생성된 segment를 네트워크 계층(IP)으로 전달하여 실제 네트워크를 통해 전송된다.
Transport Layer Actions

수신자(Receiver)
- segment를 IP로 부터 받음
- 수신자는 network layer(IP)으로부터 segment를 전달받는다.
- 헤더 값을 확인(checks header value)
- 세그먼트의 헤더 값을 확인하여 데이터의 무결성을 검증하고, 세그먼트가 올바르게 도착했는지 확인
- 어플리케이션 계층 메시지를 추출(extract application-layer message)
- 세그먼트에서 application-layer message를 추출한다. 즉, 데이터 부분을 꺼낸다.
- socket을 통해 application으로 메시지를 전달(demultiplexes message up to application via socket)
- 소켓을 통해 추출된 메시지를 어플리케이션 계층으로 전달. 이 과정은 여러 어플리케이션 프로세스가 하나의 네트워크 연결을 공유할 때, 각 메시지를 올바른 프로세스에 전달하기 위해 수행
Two Principle Internet Transport Protocols
- TCP(Transmission Control Protocol)
- Reliable, in-order delivery(신뢰할 수 있는 순서대로의 전달)
- 데이터를 신뢰성 있게, 순서대로 전달한다.
- Congestion control(혼잡 제어)
- 네트워크 혼잡을 방지하기 위해 데이터 전송 속도를 조절한다
- Flow Control(흐름 제어)
- 송신자와 수신자 간의 데이터 전송 속도를 조절하여 수신자가 과부하되지 않도록 한다.
- Connection Setup(연결 설정)
- 데이터를 전송하기 전에 송신자와 수신자 간에 연결을 설정한다.
- Reliable, in-order delivery(신뢰할 수 있는 순서대로의 전달)
- UDP(User Datagram Protocol)
- Unreliable, unordered delivery(신뢰할 수 없는, 순서가 없는 전달)
- 데이터를 신뢰성 없이, 순서에 상관없이 전달
- No-frills extension of "best-effort" IP("최선 노력" IP의 단순한 확장)
- IP 프로토콜의 "최선 노력" 서비스를 그대로 사용하며 추가적인 기능이 없다.
- Unreliable, unordered delivery(신뢰할 수 없는, 순서가 없는 전달)
- Services not available(제공되지 않는 서비스)
- Delay guarantees(지연 보상)
- 전송 지연을 보장하지 않는다.
- Bandwidth guarantees(대역폭 보장)
- 대역폭을 보장하지 않는다.
- Delay guarantees(지연 보상)

Multiplexing and demultiplexing

- 클라이언트
- 여러 어플리케이션(e.g. Skype, Netflix, Firefox)이 실행되고 있다.
- 전송 계층에서 응용 계층으로 HTTP 메시지가 전달된다.
- HTTP 서버
- Apache HTTP 서버가 실행 중이다.
- 서버는 HTTP 메시지를 송신하고 있다.
- 네트워크
- 클라이언트와 서버 간의 네트워크 연결을 통해 데이터가 전달된다.

- HTTP 서버
- 서버는 네트워크 계층을 통해 전달된 HTTP 메시지를 송선힌다.
- 메시지는 전송 계층으로 전달되어 header를 포함한 HTTP 메시지가 된다.

- HTTP 서버
- 전송 계층에서 네트워크 계층으로 전달될 때 Hn가 추가된다.

- 네트워크: 클라이언트와 서버 간의 네트워크 연결을 통해 데이터가 전달된다.

- 다수의 클라이언트
- 두 개의 클라이언트(client1, client2)가 서버에 연결되어 있다.
- 각 클라이언트는 어플리케이션 계층을 통해 HTTP 메시지를 서버로 전송한다.
Multiplexing/demultiplexing

Multiplexing at Sender(송신 측 다중화)
여러 소켓에서 데이터 처리(handle data from multiple sockets)
- 송신 측에서는 여러 어플리케이션 프로세스에서 전송되는 데이터를 처리한다.
- 각 프로세스는 독립적인 소켓을 통해 데이터를 전송한다.
transport 헤더 추가(add trasnport header)
- 각 소켓에서 온 데이터에 전송 헤더를 추가한다.
- 이 헤더 정보는 나중에 demultiplexing 과정에서 사용된다.
과정 요약
- 송신 측 다중화는 여러 소켓으로부터 데이터를 수집하고, 각 데이터에 전송 헤더를 추가하여 하나의 네트워크 스트림을 결합한다.
Demultiplexing at Receiver(수신 측 역다중화)
헤더 정보 사용(use header info)
- 수신 측에서는 각 세그먼트의 헤더 정보를 사용하여 데이터의 출처를 식별한다.
올바른 소켓으로 세그먼트 전달(deliver received segments to correct socket)
- 헤더 정보를 기반으로 각 세그먼트를 올바른 소켓으로 전달한다.
- 각 소켓은 해당 소켓에 연결된 어플리케이션 프로세스로 데이터를 전달한다.
과정 요약:
- 수신 측 역다중화는 수신된 데이터 세그먼트의 헤더 정보를 분석하여 이를 올바른 소켓으로 전달한다. 이를 통해 데이터를 원래의 어플리케이션 프로세스로 정확하게 전달할 수 있다.
- 네트워크 계층 모델
- 클라이언트
- 여러 어플리케이션 프로세스(P1, P3)에서 데이터를 전송한다.
- 전송 계층에서 각 데이터에 헤더를 추가하고 네트워크 계층으로 보낸다.
- 서버
- 네트워크 계층을 통해 수신된 데이터를 전송 계층에서 처리한다.
- 전송 계층 헤더를 분석하여 각 데이터 세그먼트를 올바른 어플리케이션 프로세스(P2, P4)로 전달한다.
- 클라이언트
How demultiplexing works
- 네트워크 계층의 패킷을 "데이터그램"
- 전송 계층의 패킷을 "세그먼트"
- 호스트가 IP 데이터그램을 수신(host receives IP datagram)
- 호스트는 네트워크를 통해 IP 데이터그램을 수신한다.
- 각 데이터그램(네트워크)에는 출발지 IP 주소와 목적지 IP 주소가 포함되어 있다.
- 각 데이터그램은 하나의 전송 계층 세그먼트를 포함한다.
- 각 세그먼트(전송)에는 출발지 포트 번호와 목적지 포트 번호가 포함되어 있다.
- IP 주소 및 포트 번호 사용(uses IP address & port numbers)
- 호스트는 수신한 세그먼트(전송 계층)를 적절한 소켓으로 전달하기 위해 IP주소와 포트 번호를 사용한다.
- 이 정보를 바탕으로 세그먼트를 올바른 어플리케이션 프로세스로 전달한다.

TCP/UDP 세그먼트 포맷
- Source port # (출발지 포트 번호)
- 세그먼트가 발송된 출발지 포트를 나타냄
- 32비트 크기
- Destination port # (목적지 포트 번호)
- 세그먼트가 도착해야 할 목적지 포트를 나타냄
- 32비트 크기
- Other header fields(기타 헤더 필드)
- 세그먼트의 다른 헤더 정보를 포함
- Application data(어플리케이션 데이터, payload)
- 실제로 전달되는 데이터
- 어플리케이션 계층에서 보내는 payload이다.

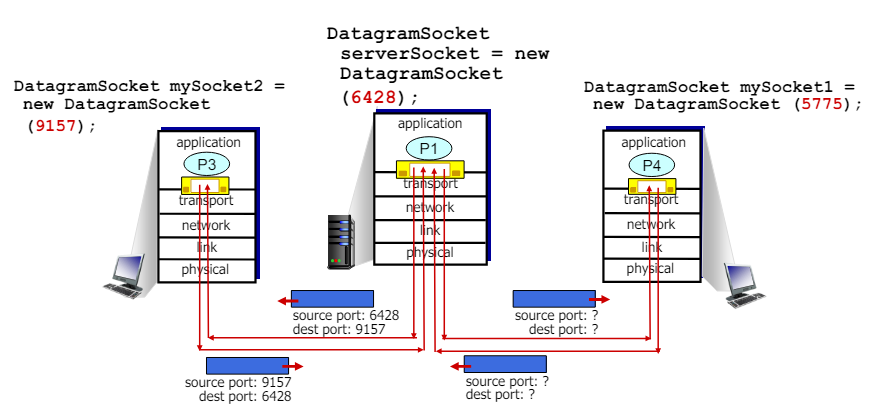
Connectionless demultiplexing
Connectionless Demultiplexing(비연결형 역다중화)
- 소켓 생성 시(When creating socket)
- 호스트 로컬 포트 번호 지정(specify host-local port #)
- 소켓을 생성할 때 호스트 로컬 포트 번호를 지정해야 한다.
- 예제 코드: 'DatagramSocket mySocket1 = new DatagramSocket(12534);'
- 호스트 로컬 포트 번호 지정(specify host-local port #)
- UDP 소켓에 데이터그램 전송 시(When Creating Datagram to send into UDP socket)
- 목적지 IP 주소 지정(specify destination IP address)
- 데이터를 전송할 목적지 IP 주소를 지정해야 한다.
- 목적지 포트 번호 지정(specify destination port #)
- 데이터를 전송할 목적지 포트 번호를 지정해야 한다.
- 목적지 IP 주소 지정(specify destination IP address)
- 수신 측에서의 처리(When receiving host receives UDP segment)
- 세그먼트의 목적지 포트 번호 확인(checks destination port # in segment)
- 수신 측에서는 세그먼트의 목적지 포트 번호를 확인한다.
- 해당 포트 번호의 소켓으로 UDP 세그먼트 전달(directs UDP segment to socket with that port #)
- 확인된 포트 번호를 기반으로 해당 소켓으로 UDP 세그먼트를 전달
- 세그먼트의 목적지 포트 번호 확인(checks destination port # in segment)
- 추가 설명
- 같은 목적지 포트 번호, 다른 출발지 IP 주소/포트 번호(IP/UDP datagrams with same dest, port #, but different source IP address and/or source port numbers)
- 동일한 목적지 포트 번호를 가진 IP/UDP 데이터그램은 출발지 IP 주소나 출발지 포트번호가 다르더라도 수신 측에서는 동일한 소켓으로 전달된다.
- 같은 목적지 포트 번호, 다른 출발지 IP 주소/포트 번호(IP/UDP datagrams with same dest, port #, but different source IP address and/or source port numbers)
Connectionless demultiplexing: an example
Connection-oriented demultiplexing
TCP 소켓 식별(TCP socket identified by 4-tuple)
- 출발지 IP 주소(source IP address)
- 출발지 포트 번호(source port number)
- 목적지 IP 주소(destination IP address)
- 목적지 포트 번호(destination port number)
역다중화 과정(demux: receiver uses all four values(4-tuple) to direct segment to appropriate socket)
- 수신자는 이 네 가지 값(4-tuple)을 사용하여 수신된 세그먼트를 적절한 소켓으로 전달한다.
서버에서의 다중 TCP 소켓 지원(server may support many simultaneous TCP sockets)
- 서버는 동시에 여러 TCP 소켓을 지원할 수 있다.
- 각 소켓은 고유한 4-tuple로 식별된다.
- 각 소켓은 서로 다른 클라이언트와의 연결에 대응한다.
Connection-oriented demultiplexing: example
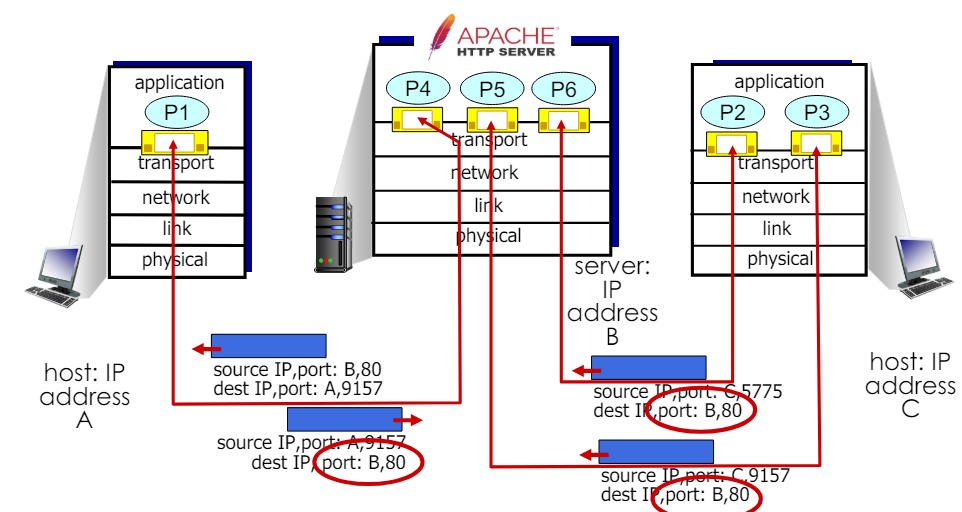
서로 다른 소켓으로 전달: 동일 서버의 동일한 포트(80) 로 데이터가 전달되지만, 출발지 IP주소와 포트 번호가 다르기 때문에 각 세그먼트는 서로 다른 소켓으로 전달된다.
port number는 기본적으로 네트워크 통신에서 데이터가 어떤 어플리케이션으로 전달되어야 하는지를 식별하는 데 사용된다
그러나 실제로는 출발지 IP 주소와 출발지 포트 번호도 함께 고려하여 데이터를 적절한 소켓으로 라우팅한다. 이를 TCP/IP 프로토콜에서는 4-tuple이라고 부른다.
Summary
- Multiplexng, demultiplexing: datagram의 header field value와 segment 기반
- UDP: 오직 destination port number만을 사용해 demultiplexing
- TCP: 4-tuple을 사용해 demultiplexing한다.(source and destination IP address와 port number)
- Multiplexing, demultiplexing은 all layer에서 일어난다.
Connectionless transport: UDP
UDP: User Datagram Protocol
특성(Characteristics)
- "no frills", "bare bones" internet transport protocol
- 추가 기능 없이 기본적인 인터넷 전송 프로토콜이다.
- 'best effort' server, UDP segments may be:
- lost:
- UDP 세그먼트는 손실될 수 있다.
- delivered out-of-order to app
- 세그먼트가 어플리케이션에 순서가 바뀌어 도착할 수 있다.
- lost:
- connectionless
- no handshaking between UDP sender, receiver
- 송신자와 수신자 간의 핸드셰이킹(handshaking)이 없다.
- each UDP segment handled independently of others
- 각 UDP 세그먼트는 다른 세그먼트와 독립적으로 처리된다.
- 각 UDP 세그먼트는 다른 세그먼트와 독립적으로 처리된다.
- no handshaking between UDP sender, receiver
왜 UDP를 사용하는가?
- 장점(Advantages)
- no connection establishment(which can add RTT delay)
- 연걸 설정이 없으므로 RTT(Round-Trip Time) 지연이 추가되지 않는다.
- simple: no connection state at sender, receiver
- 송신자와 수신자에서 연결 상태를 유지하지 않기에 간단하다.
- small header size:
- 헤더 크기가 작다.
- no congetion control
- UDP는 원하는 만큼 빠르게 데이터를 전송할 수 있다.
- 혼잡 상황에서도 동작할 수 있다.
- no connection establishment(which can add RTT delay)
UDP: User Datagram Protocol
UDP 사용 사례(UDP uses)
- Streaming multimedia apps(loss tolerant, rate sensitvie)
- DNS(Domain Name System)
- SNMP(Simple Network Management Protocol)
- HTTP/3
UDP 위에서 신뢰할 수 있는 전송이 필요한 경우(if reliable transfer needed over UDP, e.g. HTTP/3)
- add needed reliability at application layer
- 신뢰성이 필요한 경우 어플리케이션 계층에서 필요한 신뢰성을 추가한다.
- e.g. 패킷 손실 복구, 패킷 재전송 등의 메커니즘을 어플리케이션 계층에서 구현한다.
- add congestion control at application layer
- congestion control이 필요한 경우 어플리케이션 계층에서 혼잡 제어 메커니즘을 추가한다.
- e.g. 전송 속도 조절, 패킷 손실에 따른 대처 등을 어플리케이션 계층에서 관리한다.
UDP: User Datagram Protocol

User Datagram Protocol(UDP)
- 패킷 교환 방식의 컴퓨터 통신을 위해 설계된 데이터그램 모드를 제공한다.
- 인터넷 프로토콜(IP)을 기반 프로토콜을 사용한다고 가정하자.
목적
- UDP는 최소한의 프로토콜 메커니즘으로 어플리케이션 프로그램이 다른 프로그램으로 메시지를 보내기 위한 절차를 제공한다.
- 이 프로토콜은 트랜잭션 지향(각 데이터그램이 독립적으로 처리된다는 것을 의미)이며, 데이터의 전달 및 중복 보호가 보장되지 않는다.
- 순차적이고 신뢰할 수 있는 데이터 전송이 필요한 어플리케이션은 TCP(Transmission Control Protocol)을 사용해야 한다.
Format
Source Port(출발지 포트)
- 데이터그램을 보낸 출발지 포트 번호를 나타낸다.
- 16bit
Destination Port(목적지 포트)
- 데이터그램을 받을 목적지 포트 번호를 나타낸다.
- 16bit
Length(길이)
- UDP 헤더와 데이터의 총 길이를 나타낸다.
- 16bit
Checksum(체크섬)
- 데이터그램의 무결성을 확인하기 위한 체크섬 값
- 16bit
Data
- 전송할 실제 데이터
- 길이는 UDP 헤더의 길이 필드에 의해 결정된다.
UDP: Transport Layer Actions

UDP sender actions
- 응용 계층의 메시지 전달
- UDP 송신자는 응용 계층에서 전달된 SNMP 메시지를 받는다.
- UDP 송신자는 응용 계층에서 전달된 SNMP 메시지를 받는다.
- UDP segment header field 값 결정
- UDP 송신자는 UDP 세그먼트의 헤더 필드 값을 결정한다. 이는 출발지 포트 번호, 목적지 포트 번호, 길이, 체크섬 등을 포함한다.
- UDP 송신자는 UDP 세그먼트의 헤더 필드 값을 결정한다. 이는 출발지 포트 번호, 목적지 포트 번호, 길이, 체크섬 등을 포함한다.
- UDP 세그먼트 생성
- UDP 송신자는 SNMP 메시지를 포함하여 UDP 세그먼트를 생성한다. 이 세그먼트는 헤더와 데이터로 구성된다.
- UDP 송신자는 SNMP 메시지를 포함하여 UDP 세그먼트를 생성한다. 이 세그먼트는 헤더와 데이터로 구성된다.
- 세그먼트를 IP 계층으로 전달
- 생성된 UDP 세그먼트는 네트워크 계층(IP)으로 전달되어 전송된다.

UDP receiver actions
- IP 계층에서 세그먼트를 수신
- UDP 수신자는 네트워크 계층(IP)으로부터 UDP segment를 수신한다.
- UDP 수신자는 네트워크 계층(IP)으로부터 UDP segment를 수신한다.
- UDP 체크섬 헤더 값을 확인
- UDP 수신자는 세그먼트의 체크섬 헤더 값을 확인하여 데이터의 무결성을 검증
- UDP 수신자는 세그먼트의 체크섬 헤더 값을 확인하여 데이터의 무결성을 검증
- 응용 계층 메시지를 추출
- UDP 수신자는 세그먼트의 응용 계층 메시지(SNMP 메시지)를 추출한다.
- UDP 수신자는 세그먼트의 응용 계층 메시지(SNMP 메시지)를 추출한다.
- 메시지를 소켓을 통해 어플리케이션으로 전달(demultiplexes message up to application via socket)
- 추출된 메시지를 소켓을 통해 어플리케이션 계층으로 전달
UDP segment header
- 출발지 포트 번호(Source Port Number)
- 위치: UDP segment의 첫 번째 16비트
- 역할: 송신자의 포트 번호를 나타낸다. 수신자가 응답을 보낼 때 사용된다.
- 목적지 포트 번호(Destination Port Number)
- 위치: UDP segment의 두 번째 16비트
- 역할: 수신자의 포트 번호를 나타낸다. 이 포트 번호를 사용하여 데이터가 올바른 어플리케이션으로 전달된다.
- 길이(Length)
- 위치: UDP segment의 세 번째 !6비트
- 역할: UDP segment의 전체 길이를 나타낸다. 여기에는 헤더와 데이터(payload)가 모두 포함된다. 길이는 바이트 단위로 표시된다.
- 체크섬(Checksum)
- 위치: UDP segment의 네 번째 16비트
- 역할: 데이터의 무결성을 확인하기 위한 값이다. 송신자는 세그먼트를 생성할 때 체크섬을 계산하고, 수신자는 이름 검증하여 데이터가 손상되지 않았는지 확인한다.
- application data, payload
- 위치: UDP 헤더 다음에 위치
- 역할: application layer에서 전송된 실제 데이터이다. UDP는 데이터의 구조나 내용에 대해 신경 쓰지 않으며, 단순히 전송 역할을 수행한다.
UDP checksum
Goal: 전송된 segment의 error(i.e. flipped bits) 감지
Sender(송신자 측)
- UDP 세그먼트 내용 처리(treat contents of UDP segment)
- UDP 세그먼트의 모든 내용을 16비트 정수의 연속으로 취급한다. 여기에는 UDP 헤더 필드와 IP 주소도 포함된다.
체크섬 계산(checksum)
- 세그먼트 내용의 합계를 계산한다. 이 때 1의 보수 합(one's complement sum)을 사용한다.
- 세그먼트 내용의 합계를 계산한다. 이 때 1의 보수 합(one's complement sum)을 사용한다.
체크섬 필드에 값 넣기(checksum value put into UDP checksum field)
- 계산된 체크섬 값을 UDP 체크섬 필드에 넣는다.
- 계산된 체크섬 값을 UDP 체크섬 필드에 넣는다.
Receiver(수신자 측)
- 수신된 세그먼트의 체크섬 계산(compute checksum of received segment)
- 수신자는 수신된 세그먼트의 내용을 이용해 체크섬을 다시 계산한다.
- 계산된 체크섬과 필드 값 비교(check if computed checksum equals checksum field value)
- 계산된 체크섬이 UDP 세그먼트의 체크섬 필드 값과 동일한지 확인한다.
- 동일하지 않음(Not equal): 오류가 감지된다.
- 동일함(Equal): 오류가 감지되지 않음. 그러나 오류가 없다는 보장은 아니다.
- 계산된 체크섬이 UDP 세그먼트의 체크섬 필드 값과 동일한지 확인한다.
Internet Checksum: an example

wraparound: 최상위 비트(carryout)가 발생한 경우 이를 하위 비트에 더해준다.
checksum: 합계의 1의 보수를 계산한다.
Internet checksum: weak protecton

전달된 값이 에러로 인해 변경되었지만, 이는 checksum에서 감지하지 못한다.
Summary: UDP
- "No frills" 프로토콜
- 세그먼트가 손실되거나 순서가 바뀌어 전달될 수 있음
- UDP는 신뢰성 있는 전송을 보장하지 않으므로, 데이터그램이 손실되거나 순서가 바뀌어 도착할 수 있다.
- send and hope for the best
- UDP는 데이터를 전송하기 위해 연결을 설정하지 않으며, 데이터를 최선의 노력으로 전송한다. 즉, 송신 후 수신 여부를 확인하지 않는다.
- 세그먼트가 손실되거나 순서가 바뀌어 전달될 수 있음
- UDP의 장점
- no setup/handshaking needed
- 연결을 설정하는 과정이 없으므로, 추가적인 왕복 시간 지연(RTT)이 발생하지 않는다.
- 네트워크 서비스가 손상되었을 때도 동작 가능
- 네트워크 혼잡이나 손상이 발생해도 UDP는 계속해서 데이터를 전송할 수 있다.
- 신뢰성 향상에 도움(helps with reliability)
- UDP는 체크섬을 사용하여 데이터 무결성을 확인하고, 기본적인 오류 검출을 제공한다.
- no setup/handshaking needed
- 어플리케이션 계층에서 UDP 위에 추가 기능 구축(build additional functionality on top of UDP in application layer)
- e.g. HTTP/3와 같은 프로토콜은 UDP 위에 추가적인 기능을 구축하여, 신뢰성 있는 데이터 전송 및 혼잡 제어를 응용 계층에서 구현할 수 있다.
Principles of reliable data transfer
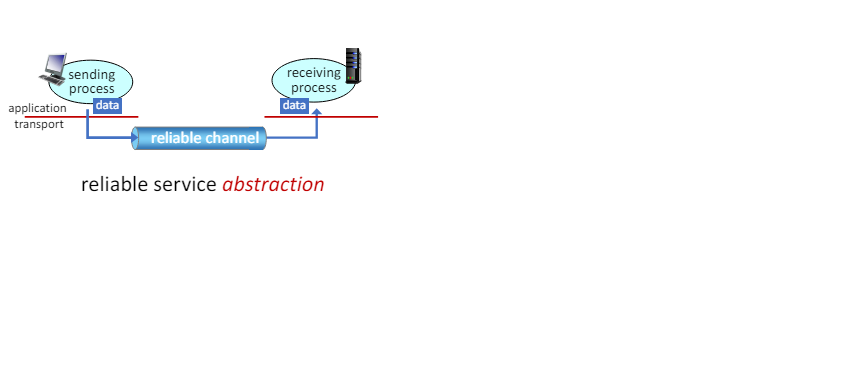


주요 구성 요소 1. 송신 프로세스(Sending Process) - 어플리케이션 데이터가 생성된다. - 데이터를 신뢰할 수 있는 데이터 전송 프로토콜의 송신 측에 전달한다.
2. 신뢰할 수 있는 데이터 전송 프로토콜의 송신 측(Sender-side of Reliable Data Transfer Protocol) - 데이터의 무결성과 전달을 보장하기 위한 메커니즘을 포함한다. - 데이터가 손실, 손상 또는 재정렬될 수 있는 신뢰할 수 없는 채널을 통해 전송된다.
3. 신뢰할 수 없는 채널(Unreliable Channel) - 데이터가 손실되거나, 손상되거나, 재정렬될 수 있는 전송 매체이다 - 신뢰할 수 있는 데이터 전송 프로토콜은 이러한 불확실성을 극복하기 위한 기능을 제공한다.
- 신뢰할 수 있는 데이터 전송 프로토콜의 수신 측(Receiver-side of Reliable Data Transfer Protocol)
- 수신된 데이터의 무결성을 확인하고, 손상된 데이터를 감지하여 필요한 경우 재전송을 요청한다
- 데이터를 수신 프로세스에 전달한다.
5. 수신 프로세스(Receiving Process) - 수신된 데이터를 어플리케이션 계층에서 처리한다.
요약
- 신뢰할 수 있는 데이터 전송 프로토콜(Reliable data transfer protocol)은 데이터 전송 중 발생할 수 있는 다양한 문제를 해결하기 위한 메커니즘을 제공한다.
- 송신 측은 데이터 검증 및 재전송 요청 처리 등의 기능을 통해 데이터의 무결성을 보장한다.
- 수신 측은 수신된 데이터의 무결성을 확인하고, 필요한 경우 재전송을 요청한다
- 신뢰할 수 없는 채널을 통해 데이터가 전송되더라도, 이러한 프로토콜을 통해 신뢰할 수 있는 데이터 전송을 구현할 수 있다.

송신자와 수신자는 서로의 상태를 알지 못함(Sender, receiver do not know the 'state' of each other)
- 송신자와 수신자는 메시지가 성공적으로 수신되었는지 여부를 알지 못한다.
- e.g. 송신자는 메시지가 수신자에게 도착했는지, 수신자는 메시지를 송신자가 보냈는지 모른다.
메시지를 통해 상태를 통신해야 함(unless communicated via a message)
- 송신자와 수신자는 메시지를 통해서만 서로의 상태를 알 수 있다.
- 즉, 수신자는 확인 응답(ACK) 메시지를 송신자에게 보내 메시지를 성공적으로 수신했음을 알릴 수 있다.
Reliable data transfer protocol(rdt) : interfaces
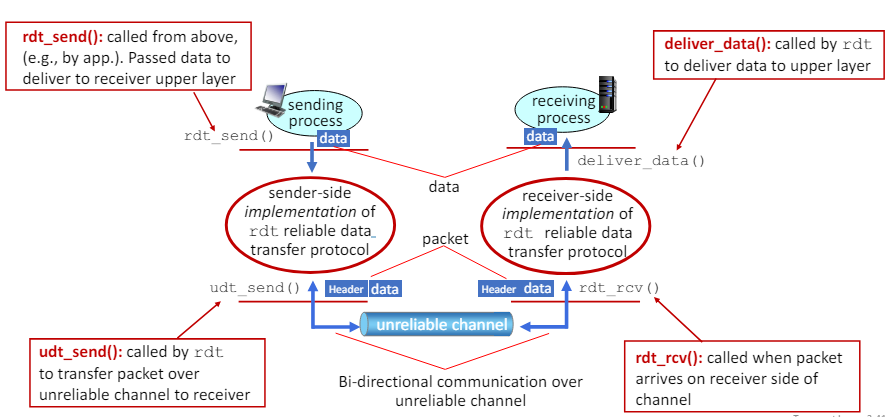
송신 측(Sender Side)
- rdt_send()
- 역할: 응용 계층에서 데이터를 받아 수신자의 상위 계층으로 전달하기 위해 호출된다.
- 설명: 송신 프로세스에서 데이터를 받아 rdt protocol의 송신측 구현으로 전달한다.
- udt_send()
- 역할: 신뢰할 수 없는 채널을 통해 패킷을 전송하기 위해 rdt에 의해 호출된다.
- 설명: 신뢰할 수 없는 채널을 통해 수신자에게 패킷을 전송한다.
수신 측(Receiver Side)
- rdt_rcv()
- 역할: 신뢰할 수 없는 채널을 통해 패킷이 수신 측에 도착하면 호출된다.
- 설명: 패킷이 수신자 측에 도착할 때마다 rdt protocol의 수신 측 구현으로 전달된다.
- deliver_data()
- 역할: 데이터를 상위 계층으로 전달하기 위해 rdt에 의해 호출된다.
- 설명: rdt protocol의 수신 측 구현에서 데이터를 수신 프로세스로 전달한다.
사진 설명
- Sending Process(송신 프로세스)
- 응용 계층에서 data를 생성
- rdt_send()를 호출하여 data를 신뢰할 수 있는 데이터 전송 프로토콜의 송신 측 구현으로 전달한다.
- Sender-side Implementation(송신 측 구현)
- rdt_send()에서 받은 데이터를 udt_send()를 호출하여 신뢰할 수 없는 채널을 통해 packet으로 전송
- Unreliable Channel(신뢰할 수 없는 채널)
- 데이터를 패킷으로 전송
- 패킷은 수신 측으로 전달됨
- Receiver-side Implementation(수신 측 구현)
- rdt_rcv()가 호출되어 신뢰할 수 없는 채널을 통해 도착한 패킷을 처리한다.
- 패킷에서 데이터를 추출하여 deliver_data()를 호출하여 데이터를 수신 프로세스에 전달한다.
- Receiving Process(수신 프로세스)
- deliver_data()를 통해 전달된 데이터를 상위 계층에서 처리
Reliable data transfer: getting started
점진적으로 송신자와 수신자 측 개발(incrementally develop sender, receiver sides of RDT)
- 신뢰할 수 있는 데이터 전송 프로토콜(RDT)의 송신자와 수신자 측을 점진적으로 개발
- 각 단계에서 프로토콜의 복잡성을 증가시켜 나간다.
단방향 데이터 전송만 고려(consider only unidirectional data transfer)
- 여기서는 단방향 데이터 전송만을 고려
- 하지만, 제어 정보는 양방향으로 흐른다. 즉, 데이터는 한 방향으로만 흐르지만, 확인 응답(ACK)이나 재전송 요청 등의 제어 정보는 반대 방향으로도 전송된다.
- 유한 상태 기계(FSM) 사용(use finite state machines to specify sender, receiver)
- 송신자와 수신자를 정의하기 위해 유한 상태 기계를 사용한다.
- 각 상태는 다음 상태로의 전이를 일으키는 이벤트와 상태 전이 시 수행되는 동작을 포함한다.

rdt1.0: reliable transfer over a reliable channel
- 기본 가정(Underlying Assumptions
- 완벽히 신뢰할 수 있는 채널(underlying channel perfectly reliable)
- 비트 오류 없음(no bit errors): 데이터 전송 중에 비트 오류가 발생하지 않는다.
- 패킷 손실 없음(no loss of packets): 데이터 전송 중에 패킷 손실이 발생하지 않는다.
- 완벽히 신뢰할 수 있는 채널(underlying channel perfectly reliable)
송신자와 수신자를 위한 별도의 FSM(Separate FSMs for sender and receiver)
- 송신자(Sender)
- 동작:
- 상위 계층에서 데이터 전송 요청이 있을 때까지 대기한다.('Wait for call from above')
- 'rdt_send(data)' 함수가 호출되면 데이터를 패킷으로 만든다('packet = make_pkt(data)')
- 패킷을 신뢰할 수 있는 채널을 통해 전송한다.('udt_send(packet)')
- 동작:
- 수신자(Receiver)
- 동작:
- 하위 계층에서 패킷이 도착할 때까지 대기한다.('Wait for call from below')
- 'rdt_rcv(packet)' 함수가 호출되면 패킷에서 데이터를 추출한다.('extract(packet, data)')
- 추출한 데이터를 상위 계층으로 전달한다. ('deliver_data(data)')
- 동작:
rdt 2.0 : channel with bit errors
채널에서 패킷 내의 비트가 변경될 수 있다. 즉, 데이터 전송 중에 비트 오류가 발생할 수 있다.
- checksum(e.g. Internet checksum)이 bit error를 detect할 수 있다.
- 송신자(Sender)
Q. error를 어떻게 복구할 것인가?
- ACKs(Acknowledgements): 수신자는 송신자에게 패킷이 정상적으로 수신되었음을 명시적으로 알린다.
- NAKs(Negative Acknowledgements): 수신자는 송신자에게 패킷에 오류가 있음을 명시적으로 알린다.
- Retransmission: 송신자는 NACK를 수신하면 패킷을 재전송한다.
Stop-and-Wait 프로토콜
- 송신자는 한 번에 하나의 패킷을 전송하고, 수신자로부터 응답을 기다린다
- 수신자가 ACK를 보내면 다음 패킷을 전송한다.
- 수신자가 NAK를 보내면 송신자는 동일한 패킷을 재전송한다.
rdt2.0: FSM specifications

상태(State)
- Wait for call from above(상위 계층으로부터 호출 대기)
- 송신자는 상위 계층(응용 계층)에서 데이터 전송 요청이 있을 때까지 대기한다.
- Wait for ACK or NAK
- 송신자는 데이터를 전송한 후, 수신자로부터 ACK(확인 응답) 또는 NAK(부정 응답)를 기다린다.
상태 전이(State Transition)
- Wait for call from above -> Wait for ACK or NAK
- 조건: 상위 계층에서 데이터 전송 요청이 있을 때('rdt_send(data)')
- 동작:
- 데이터와 체크섬을 포함하는 패킷을 생성('snkpkt = make_pkt(data, checksum)')
- 생성된 패킷을 신뢰할 수 없는 채널을 통해 전송('udt_send(snkpkt)')
- Wait for ACK or NAK -> Wait for call from above
- 조건: 수신된 패킷이 ACK인 경우('rdt_rcv(rcvpkt) && isACK(rcvpkt)')
- 동작:
- ACK를 받으면 송신자는 상위 계층에서 다음 데이터 전송 요청을 기다린다.
- Wait for ACK or NAK -> Wait for ACK or NAK
- 조건: 수신된 패킷이 NAK인 경우('rdt_rcv(rcvpkt) && isNAK(rcvpkt)')
- 동작:
- NAK를 받으면 송신자는 이전에 전송한 패킷을 다시 전송한다. ('udt_send(snkpkt)')
Note
- "state"의 수신자는 송신자가 알 수 없다. 즉, 수신자가 메시지를 제대로 받았는지 여부를 송신자가 알 수 없다.
- 이는 수신자가 송신자에게 ACK 또는 NAK를 통해 명시적으로 알려주지 않으면 송신자가 알 수 없음을 의미한다.
- 이러한 이유로, 송신자가 수신자 간의 통신을 관리하는 프로토콜이 필요하다.
rdt2.0: operation with no erros

수신자(Receiver) FSM가 추가됬다.
- 상태: Wait for call from below(하위 계층으로부터 호출 대기)
- 동작: 하위 계층에서 패킷이 도착할 때까지 대기한다.
- 이벤트: 'rdt_rcv(rcvpkt) && corrupt(rcvpkt)
- 작업: 수신된 패킷에 오류가 있는 경우, NAK를 전송한다.('udt_send(NAK)')
- 전이: 상태는 "Wait for call from below"로 유지
- 이벤트: rdt_rcv(rcvpkt) && notcorrupt(rcvpkt)
- 작업: 수신된 패킷에 오류가 없는 경우, 데이터를 추출하고('extrack(rcvpkt, data)'), 상위 계층으로 전달한다.('deliver_data(data)'). 그리고 ACK를 전송한다.('udt_send(ACK)')
- 전이: 상태를 'Wait for call from below'

rdt2.0 has a fatal flaw
What happens if ACK/NAK corrupted?
- 송신자가 수신자의 상태를 알 수 없음
- ACK 또는 NAK가 손상된 경우, 송신자는 수신자가 패킷을 올바르게 수신했는지 여부를 알 수 없다.
- 단순 재전송 불가능
- 송신자가 패킷을 단순히 재전송할 수 없다. 이는 중복 패킷이 발생할 수 있기 때문이다.
- 중복 패킷은 수신자가 동일한 데이터를 여러 번 수신하게 할 수 있다.
Handling Duplicates
- 손상된 ACK/NAK에 대한 재전송(sender retransmits current pkt if ACK/NAK corrupted)
- 송신자가 ACK 또는 NAK가 손상된 경우, 현재 패킷을 재전송한다.
- 순서 번호 추가(sender adds sequence number to each pkt)
- 송신자는 각 패킷에 순서 번호를 추가하여 중복을 식별할 수 있게 한다.
- 순서 번호를 통해 수신자는 중복 패킷을 감지하고 무시할 수 있다.
- 수신자가 중복 패킷을 버림(receiver discards (doesn't deliver up) duplicate pkt)
- 수신자는 중복 패킷을 식별하여 이를 상위 계층으로 전달하지 않고 버린다.
Stop-and-Wait 프로토콜
- 송신자는 한 번에 하나의 패킷을 전송하고, 수신자의 응답(ACK, NAK)을 기다린다
- 이는 데이터 전송의 신뢰성을 보장하기 위한 기본적인 흐름 제어 방식이다..
rdt2.1: Sender, Handling garbled ACK/NAKs

순서 번호 0,1을 통해 중복 패킷을 식별하고 처리
상태(state)
- Wait for call 0 from above
- 동작: 상위 계층에서 데이터 전송 요청이 있을 때까지 대기한다.
- 이벤트: 'rdt_send(data)'
- 작업: 순서 번호 0과 데이터를 포함하는 패킷을 생성('sndpkt = make_pkt(0, data, checksum)')하고 전송('udt_send(sndpkt)')
- 전이: 상태가 'Wait for ACK or NAK 0'로 전이된다
- Wait for ACK or NAK 0
- 동작: 패킷 전송 후, 수신자로부터 ACK 또는 NAK를 기다린다.
- 이벤트: 'rdt_rcv(rcvpkt) && (corrupt(rcvpkt) || isNAK(rcvpkt))'
- 작업: 수신된 패킷이 손상되었거나 NAK인 경우, 현재 패킷을 다시 전송('udt_send(sndpkt)')
- 전이: 상태는 'Wait for ACK or NAK 0'로 유지된다.
- 이벤트 'rdt_rcv(rcvpkt) && notcorrupt(rcvpkt) && isACK(rcvpkt)
- 작업: 수신된 패킷이 손상되지 않았고 ACK인 경우, 다음 데이터 전송 요청을 기다린다.
- 전이: 상태는 'Wait for call 1 from above'로 전이된다.
- Wait for call 1 from above
- 동작: 상위 계층에서 데이터 전송 요청이 있을 때까지 대기한다.
- 이벤트: 'rdt_send(data)'
- 작업: 순서 번호 1과 데이터를 포함하는 패킷을 생성('sndpkt = make_pkt(1, data, checksum)')하고 전송('udt_send(sndpkt)')
- 전이: 상태가 'Wait for ACK or NAK 1'로 전이된다.
- Wait for ACK or NAK 1
- 동작: 패킷 전송 후, 수신자로부터 ACK 또는 NAK를 기다린다.
- 이벤트: 'rdt_rcv(rcvpkt) && (corrupt(rcvpkt) || isNAK(rcvpkt))
- 작업: 수신된 패킷이 손상되었거나 NAK인 경우, 현재 패킷을 다시 전송('udt_send(sndpkt)')
- 전이: 상태는 "Wait for ACK or NAK 1"로 유지
- 이벤트: 'rdt_rcv(rcvpkt) && notcorrupt(rcvpkt) && isACK(rcvpkt)
- 작업: 수신된 패킷이 손상되지 않았고 ACK인 경우, 다음 데이터 전송 요청을 기다림
- 전이: 상태가 "Wait for call 0 from above"로 전이된다.
rdt2.1 : receiver, handling garbled ACK/NAKs

상태(state)
- Wait for 0 from below
- 동작: 하위 계층에서 순서 번호 0의 패킷이 도착할 때까지 대기
- 이벤트: 'rdt_rcv(rcvpkt) && corrupt(rcvpkt)
- 작업: 수신된 패킷이 손상된 경우, NAK 패킷을 생성('sndpkt = make_pkt(NAK, chksum)')하고 전송('udt_send(sndpkt)')
- 전이: 상태는 "Wait for 0 from below"로 유지된다.
- 이벤트: 'rdt_rcv(rcvpkt) && notcorrupt(rcvpkt) && has_seq0(rcvpkt)'
- 작업: 수신된 패킷이 손상되지 않았고 순서 번호 0인 경우, 데이터를 추출('extrack(rcvpkt, data)')하여 상위 계층으로 전달('deliver_data(data)')한다. ACK 패킷을 생성('snkpkt = make_pkt(ACK, chksum)')하고 전송('udt_send(sndpkt)')
- 전이: 상태가 'Wait for 1 from below'로 전이된다.
- Wait for 1 from below
- 동작: 하위 계층에서 순서 번호 1의 패킷이 도착할 때까지 대기한다.
- 이벤트: 'rdt_rcv(rcvpkt) && corrupt(rcvpkt)'
- 작업: 수신된 패킷이 손상된 경우, NAK 패킷을 생성('sndpkt = make_pkt(NAK, chksum)')하고 전송('udt_send(sndpkt)')
- 전이: 상태는 "Wait for 1 from below"로 유지된다.
- 이벤트: 'rdt_rcv(rcvpkt) && notcorrupt(rcvpkt) && has_seq1(rcvpkt)'
- 작업: 수신된 패킷이 손상되지 않았고 순서 번호 1인 경우, 데이터를 추출('extrack(rcvpkt, data)')하여 상위 계층으로 전달('deliver_data(data)')한다.
- 작업: ACK 패킷을 생성('sndpkt = make_pkt(ACK, chksum)')하고 전송('udt_send(sndpkt)').
- 전이: 상태가 "Wait for 0 from below"로 전이된다.
rdt2.1: discussion
송신자(Sender)
- 순서 번호 추가(seq # added to pkt)
- 각 패킷에 순서 번호가 추가된다. 이 번호는 송신자가 보낸 패킷이 중복되었는지 여부를 확인하는 데 사용된다.
- 두 개의 순서 번호(0,1)로 충분(two seq. #s (0,1) will suffice, why?
- 송신자는 두 개의 순서 번호(0과 1)만 사용해도 된다. 이는 송신자가 한 번에 하나의 패킷만 전송하고, 다음 패킷을 전송하기 전에 이전 패킷에 대한 확인 응답을 기다리기 때문이다.
- 각 패킷은 번갈아 가며 0 또는 1의 순서 번호를 가지므로 중복을 쉽게 식별할 수 있다.
- 수신된 ACK/NAK의 손상 여부 확인(must check if received ACK/NAK corrupted)
- 송신자는 수신된 ACK 또는 NAK가 손상되었는지 확인해야 한다. 손상된 경우에는 패킷을 재전송 해야한다.
- 두 배 많은 상태(twice as many states)
- 프로토콜은 두 배 많은 상태를 필요로 한다. 이는 송신자가 "기대하는" 패킷이 순서 번호 0인지 1인지 기억해야 하기 때문이다.
수신자(Receiver)
- 중복 패킷 여부 확인(must check if received packet is duplicate)
- 수신자는 수신된 패킷이 중복된 패킷인지 확인해야 한다.
- 상태는 기대하는 패킷의 순서 번호가 0인지 1인지 나타낸다.
- 수신자는 마지막 ACK/NAK가 송신자에게 올바르게 수신되었는지 알 수 없음(note : receiver can not know if its last ACK/NAK received OK at sender)
- 수신자는 마지막으로 보낸 ACK 또는 NAK가 송신자에게 올바르게 도착했는지 알 수 없다.
- 이는 수신자가 항상 ACK 또는 NAK를 송신자에게 보내는 이유 중 하나이다.
rdt2.2: a NAK-free protocol

- rdt2.1과 동일한 기능(same functionality as rdt2.1, using ACKs only)
- rdt2.2는 rdt2.1과 동일한 기능을 수행하지만, NAK를 사용하지 않고 ACK만을 사용한다.
- NAK 대신 ACK 사용(instead of NAK, receiver sends ACK for last pkt received OK)
- 수신자는 NAK 대신, 마지막으로 올바르게 수신된 패킷에 대한 ACK를 보낸다.
- 수신자는 ACK에 확인하는 패킷의 순서 번호를 명시적으로 포함시켜야 한다.
- 중복된 ACK에 대한 처리(duplicate ACK at sender results in same action as NAK)
- 송신자는 중복된 ACK를 수신하면, NAK를 수신한 것과 동일하게 현재 패킷을 재전송한다.
- 이는 중복된 ACK가 수신자가 이전에 수신한 패킷이 손상되었음을 나타낼 수 있기 때문이다.
- TCP의 NAK-free 접근 방식
- TCP는 이러한 접근 방식을 사용하여 NAK를 사용하지 않는다.
- TCP는 ACK만을 사용하여 신뢰할 수 있는 데이터 전송을 보장한다.
rdt3.0 : channels with errors and loss
새로운 채널 가정(New Channel Assumption)
- 기본 가정: 채널에서 데이터 패킷과 ACK(확인 응답) 패킷이 손실될 수 있다.
- 오류 및 손실 가능: 기존의 비트 오류뿐만 아니라 패킷 자체가 손실될 수 있다.
- 체크섬, 순서 번호, ACK, 재전송: 이러한 메커니즘은 도움을 줄 수 있지만, 충분하지 않다.
- 체크섬: 비트 오류를 감지
- 순서 번호: 패킷의 순서를 관리하여 중복을 방지
- ACK: 수신자가 패킷을 정상적으로 수신했음을 송신자에게 알린다.
- 재전송: 손실된 패킷을 다시 전송한다.
질문
- Q. 사람들은 대화 중에 송신자와 수신자 간의 단어가 손실되는 경우를 어떻게 처리합니까?
접근 방식:
- 송신자가 합리적인 시간 동안 ACK를 기다림(sender waits "reasonable" amount of time for ACK)
- 해당 시간 내에 ACK를 받지 못하면 재전송(retransmits if no ACK received in this time)
패킷이 지연된 경우(if pkt(or ACK) just delayed(not lost))
- 재전송된 패킷이 중복될 수 있음(retransmission will be duplicate, but seq #s already handles this!)
- 수신자가 ACK가 확인하는 패킷의 순서 번호를 명시해야 함(receiver must specify seq # of packet being ACKed)
타이머 사용(use countdown timer to interrupt after "reasonable" amount of time)
- 타이머를 사용하여 설정된 시간이 지나면 인터럽트 발생(timeout)
- 송신자는 카운트다운 타이머를 사용하여 설정된 시간 동안 ACK를 기다리고, 그 시간이 지나면 타임아웃이 발생하여 패킷을 재전송한다.
rdt3.0 sender

rdt3.0 in action


Performance of rdt3.0 (Stop-and-Wait)
활용도(Utilization)
- U_sender: 송신자의 활용도는 송신자가 데이터를 전송하는 데 바쁜 시간의 비율을 나타낸다.
예제(Example)
1 Gbps 링크(1 Gbps link):
- 링크 속도: 1 Gbps(기가비트/초)
- 링크 속도: 1 Gbps(기가비트/초)
15 ms 전파 지연(15 ms prop.delay)
- 전파 지연: 15ms(밀리초)
- 전파 지연: 15ms(밀리초)
- 8000 비트 패킷(8000 bit packet)
- 패킷 크기: 8000 bit
전송 시간 계산(Time to Transmit Packet into Channel)
- 전송 시간(D_trans)
- 전송 시간은 패킷을 채널에 전송하는 데 걸리는 시간이다.
- 계산식: Dtrans = L / R
- L : 패킷 크기(8000bit)
- R : 링크 속도(1 Gbps = 10^9 bits/sec)
- 계산: Dtrans = 8000bits / 10^9 bits/ sec = 8microseconds
- 따라서, 패킷을 채널에 전송하는 데 걸리는 시간은 8 마이크로초이다.
rdt3.0: stop-and-wait operation


- rdt 3.0 프로토콜은 성능은 좋지 않음(rdt 3.0 protocol performance stinks)
- 이 계산 결과는 송신자의 활용도가 매우 낮음을 보여준다.
- 송신자가 실제로 데이터를 전송하는 데 바쁜 시간은 전체 시간의 극히 일부분이다.
- 프로토콜이 채널의 성능을 제한함(protocol limits performance of underlying infrastructrue(channel))
- rdt3.0의 stop-and-wait 방식은 채널의 높은 대역폭을 효과적으로 사용하지 못한다.
rdt3.0: pipelined protocols operation
파이프라인 처리(pipelining)
- 정의: 송신자는 ACK를 기다리지 않고 여러 개의 "비행 중인(in-flight)" 패킷을 전송할 수 있다. 즉, 아직 확인되지 않은 여러 패킷을 한 번에 전송하는 것 이다.
파이프라인 처리를 위한 요구 사항
- 순서 번호의 범위를 증가시켜야 함(Range of Sequence Numbers Must Be Increased)
- 여러 패킷을 동시에 전송할 때, 각 패킷을 식별하기 위해 더 큰 범위의 순서 번호가 필요하다.
- 송신자와 수신자에서의 버퍼링(Buffering at Sender and/or Receiver)
- 송신자와 수신자는 아직 확인되지 않은 패킷들을 저장하기 위해 버퍼를 사용해야 한다.

Go-Back-N: sender
Go-Back-N 프로토콜: 송신자가 일정 크기의 창을 통해 여러 패킷을 전송할 수 있도록 하며, ACK를 받지 못한 패킷이 있을 경우 해당 패킷과 이후의 패킷을 모두 재전송한다.

기본 개념
- Window: 송신자는 N개의 연속적으로 전송되었지만 ACK를 받지 못한 패킷을 허용한다.
- k-bit sequence number: 패킷 헤더에 포함된 k-bit sequence number를 사용하여 패킷을 식별한다.
Window 메커니즘 설명
- send_base: 송신 창의 시작 지점, 이 지점 이전의 패킷은 이미 ACK를 받았다.
- nextseqnum: 다음으로 전송할 패킷의 순서 번호이다.
- window size N: 창의 크기는 N
누적 ACK(Cumulative ACK)
- ACK(n): n번까지의 모든 패킷에 대해 ACK를 받았음을 의미한다.
- ACK(n)을 수신한 경우: 송신자는 창을 n+1부터 시작하도록 앞으로 이동한다.
타이머와 재전송(Timer and Retransmission)
- 타이머: 비행 중인 가장 오래된 패킷에 대해 타이머를 설정하고, 타임아웃이 발생하면 해당 패킷과 이후의 패킷을 모두 재전송한다.
- timeout(n): n번 패킷과 그 이후의 모든 패킷을 재전송한다.
Go-Back-N: receiver
기본 개념
- ACK-only: 수신자는 지금까지 올바르게 수신된 패킷에 대해 가장 높은 순서 번호(in-order) 와 함께 ACK를 보낸다.
- 순서가 맞지 않는 패킷 수신 시: 수신자는 해당 패킷을 버리거나 버퍼링할 수 있으며, 이는 구현에 따라 달라진다.
수신자 동작
- 올바르게 수신된 패킷에 대해 ACK 전송
- 수신자는 지금까지 올바르게 수신된 패킷에 대해 가장 높은 순서 번호와 함께 ACK를 보낸다.
- 이는 중복된 ACK를 생성할 수 있다.
- 수신자는 'rcv_base' 만 기억하면 된다.
- 순서가 맞지 않는 패킷 수신 시
- 수신자는 순서가 맞지 않는 패킷을 수신하면 이를 버리거나 버퍼링할 수 있다.
- 패킷을 버리는 경우(버퍼에 넣지 않음), 수신자는 가장 높은 순서 번호의 패킷에 대해 다시 ACK를 보낸다.

수신자 창의 상태
- 녹색: 수신하고 ACK를 보낸 패킷이다.
- 분홍색: 수신했지만 ACK를 보내지 않은 순서가 맞지 않는 패킷이다.
- 흰색: 아직 수신하지 않은 패킷이다.

Selective repeat
선택적 반복 프로토콜에 대한 설명이다. 이 프로토콜은 Go-Back-N 프로토콜의 단점을 보완하기 위해 만들었다.
- 수신자 동작
- 수신자는 올바르게 수신된 각 패킷을 개별적(individually) 으로 확인한다.
- 필요한 경우, 상위 계층으로 순서대로 전달하기 위해 패킷을 버퍼링한다.
- 송신자 동작
- 송신자는 ACK를 받지 못한 패킷에 대해 개별적으로 타임아웃하고 재전송한다.
- 송신자는 ACK를 받지 못한 각 패킷에 대해 타이머를 유지한다.
- 송신 창
- 송신자는 N개의 연속적인 순서 번호를 가진 패킷을 전송할 수 있다.
- 이는 송신된 패킷 중 ACK를 받지 못한 패킷의 순서 번호를 제한한다.

주요 요소 설명 1. send_base - 송신 창(window)의 시작 부분을 나타낸다. 이 지점은 ACK를 받지 않은 가장 오래된 패킷의 순서 번호를 가리킨다.
2. nextseqnum - 송신자가 다음에 보낼 패킷의 순서 번호를 나타낸다. 이 지점부터 오른쪽으로 있는 패킷들은 아직 전송되지 않은 패킷이다.
3. Window Size - 송신 창의 크기를 나타낸다. 송신자는 동시에 N개의 패킷을 전송할 수 있다.
Selective Repeat: Sender and Receiver
송신자 측
- 상위 계층에서 데이터 수신
- 응용 계층에서 데이터를 보내려고 할 때, 송신자는 다음 사용할 수 있는 시퀀스 번호가 송신 창 내에 있는지 확인한다. 시퀀스 번호가 창 내에 있다면 송신자는 패킷을 생성하고 보낸다.
- 타임아웃(timeout(n))
- 패킷 n의 타이머가 만료되면 해당 패킷의 ACK(승인 응답)를 제시간에 받지 못했다는 의미이다. 송신자는 패킷 'n'을 재전송하고 해당 패킷의 타이머를 다시 시작한다.
- ACK(n)이 [sendbase, sendbase + N] 내에 있음
- 송신자가 현재 창 내에서 패킷 'n'에 대한 ACK를 받으면 해당 패킷을 받은 것으로 표시한다. 'n'이 가장 작은 미승인 패킷이라면 송신자는 창의 시작점을 다음 미승인 시퀀스 번호로 이동시킨다.
수신자 측
- packet n in [rcvbase, rcvbase + N - 1]
- send ACK(n)
- out-of-order: buffer
- in-order: 수신자는 해당 패킷을 응용 계층에 전달하고 버퍼에 저장된 순서대로 패킷을 전달하며, 수신 창을 다음 수신되지 않은 패킷으로 이동시킨다.
- packet n in [rcvbase - N, rcvbase - 1]
- 수신자가 이미 승인된 시퀀스 번호 범위 내에 있는 패킷 n을 받으면 해당 패킷에 대한 ACK를 다시 송신자에게 보낸다.
- otherwise: ignore
Selective Repeat in action
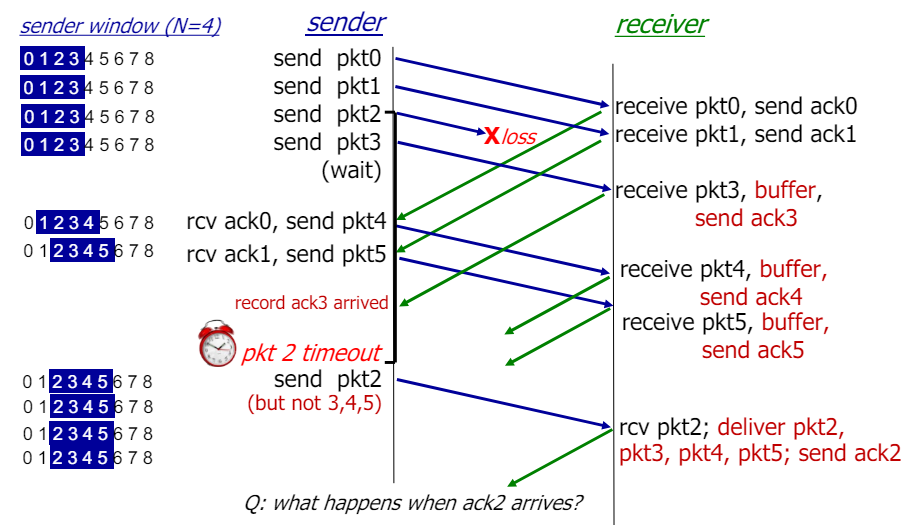
Selective repeat: a dilemma

문제 상황 b
- 송신 측: 패킷 전송 중 pkt0에 문제가 발생하여 재전송함
- 수신 측: 순서가 맞지 않는 패킷을 받으면 버퍼링하고, 순서가 맞는 패킷을 확인 응답함
- 예: pkt0 (0), ptk1 (1), pkt2 (2)가 전송되었을 때 pkt0이 손실되고 재전송됨
- 예: pkt0 (0), ptk1 (1), pkt2 (2)가 전송되었을 때 pkt0이 손실되고 재전송됨
- 문제 발생: 재전송된 pkt0이 수신될 때 수신 측이 이를 새 패킷으로 오인하고 다시 받아들이게 됨
- 이는 시퀀스 번호의 크기와 윈도우 크기 사이의 관계로 인해 발생
핵심 이슈
- 시퀀스 번호의 크기와 윈도우 크기 사이의 관계
- 시퀀스 번호 공간이 충분히 크지 않으면 재전송된 패킷이 중복으로 인식될 수 있다.
- 이 문제를 해결하려면 시퀀스 번호 공간이 윈도우 크기보다 적어도 두 배는 커야 한다.
해결 방법
- 시퀀스 번호의 크기를 늘리기: 이를 통해 패킷의 중복 문제를 방지할 수 있다.
- 윈도우 크기 조절: 윈도우 크기를 시퀀스 번호 공간에 맞춰 조정하여 중복 패킷이 발생하지 않도록 한다.
'학교수업 > 컴퓨터망' 카테고리의 다른 글
| Chapter4: Network Layer-Data Plane (0) | 2024.07.04 |
|---|---|
| Chapter3: Transport Layer-2 (0) | 2024.07.04 |
| Chapter2: Application Layer-2 (0) | 2024.07.03 |
| Chapter2: Application Layer (0) | 2024.07.01 |
| Chapter1: Introduction (0) | 2024.06.30 |