Network-layer functions
- 포워딩(Forwarding)
- 기능: 라우터의 입력에서 적절한 라우터 출력으로 패킷을 이동
- data plane
- 설명: 포워딩은 라우터의 들어오는 링크에서 나가는 링크로 패킷을 보내는 과정이다. 이는 포워딩 테이블을 기반으로 하여 실제 데이터가 네트워크를 통해 이동하는 것을 처리한다.
- 라우팅(routing)
- 기능: 패킷이 출발지에서 목적지까지 가는 경로를 결정한다.
- control plane
- 설명: 라우팅은 패킷이 목적지에 도달하기 위해 취해야 할 경로를 결정하는 작업이다. 이는 라우팅 알고리즘과 프로토콜을 사용하여 패킷이 효율적이고 정확하게 네트워크를 통해 전달되도록 한다.
network control plane을 구성하는 두 가지 접근 방식
- 라우터별 제어(전통적 방식)
- 논리적으로 중앙집중화된 제어(소프트웨어 정의 네트워킹, SDN)
Per-router control plane
- Individual routing algorithm(개별 라우팅 알고리즘)
- 각 라우터마다 개별적으로 라우팅 알고리즘이 존재하고, 이들이 control plane 에서 상호작용한다.
- 각 라우터마다 독립적으로 라우팅 테이블을 관리하고 업데이트한다.

Software-Defined Networking (SDN) control plane
- 원격 컨트롤러(Remote Controller)
- 중앙집중화된 컨트롤러가 모든 라우터의 포워딩 테이블을 계산하고 설치한다

- 구성요소
- Remote Controller: 네트워크 중앙에서 모든 라우터의 forwarding table을 관리한다.
- CA(Controller Agent): 라우터에 설치된 agent로, 컨트롤러와 통신하여 forwarding table를 받는다.
- local forwarding table: 컨트롤러가 제공한 정보를 기반으로 라우터에서 패킷을 포워딩하는 데 사용된다.
Routing Protocols
- Routing Protocol goal:
- 목표: 보내는 호스트에서 받는 호스트까지 네트워크의 라우터를 통해 'good' path를 결정하는 것
- 경로: 초기 source 호스트에서 최종 목적지 호스트까지 패킷이 거치는 라우터의 시퀀스
- 좋은 경로: 비용이 적거나. 가장 빠르거나. 가장 혼잡하지 않은 경로
- 라우팅: 상위 10개 네트워크 챌린지 중 하나로 언급됨

Graph abstraction: link costs

Routing Algorithm classification
- How fast do routes change?(경로가 얼마나 빨리 변경되는가?)
- Static(정적): 경로가 시간이 지나면서 천천히 변경된다.
- Dynamic(동적): 경로가 더 빨리 변경되며, 주기적인 업데이트나 링크 비용 변화에 반응하여 변경된다.
- Global or decentralized information?(전역 또는 분산된 정보?)
- Global(전역): 모든 라우터가 완전한 토폴로지와 링크 비용 정보를 가지고 있다.
- Decentralized(분산): 정보 교환과 계산 과정이 반복적으로 이루어지며. 라우터는 처음에 연결된 이웃 라우터에 대한 링크 비용만 알고 있다.
- "distance vercotr algorithm": 라우터는 이웃 라우터와의 정보 교환을 통해 경로를 점진적으로 계산한다. 처음에는 이웃 라우터에 대한 링크 비용만 알고있으며, 반복적인 정보 교환을 통해 전체 경로 정보를 얻게 된다.
Dijkstra's link-state routing algorithm
- centralized(중앙화된)
- 네트워크 토폴로지와 링크 비용이 모든 노드에 알려져 있다.
- "링크 상태 브로드 캐스트"를 통해 달성된다.
- 모든 노드는 동일한 정보를 가진다.
- Least Cost Paths
- 한 노드(출발지)에서 다른 모든 노드로의 최소 비용 경로를 계산한다.
- 이 과정에서 포워딩 테이블이 생성된다.
- Iterative(반복적인)
- k번의 반복 후. k개의 목적지에 대한 최소 비용 경로를 알게 된다.
- Notation(표기법)
- cx,y: 노드 x에서 y로의 직접 링크 비용. 직접 연결된 이웃이 아닐 경우 무한대로 설정된다.
- D(v): 출발지에서 목적지 v까지의 최소 비용 경로의 현재 추정치
- p(v): 출발지에서 v까지의 경로에서의 이전 노드
- N' : 최소 비용 경로가 확정적으로 알려진 노드의 집합



- Least-Cost-Path Tree: 이전 노드를 추적하여 최소 비용 경로 트리를 구성한다.
- Ties: 동일한 비용의 경로가 있을 수 있으며, 이는 임의로 선택될 수 있다.
Dijkstra's algorithm:discussion
- algorithm complexity
- 다익스트라 알고리즘은 각 반복에서 모든 노드를 검사해야 하므로 기본적으론 O(n2)의 시간 복잡도를 가진다.
- 더 효율적인 구현을 통해 O(nlogn)의 시간 복잡도를 달성할 수 있다.
- message complexity
- 각 라우터는 링크 상태 정보를 다른 모든 라우터에 브로드캐스트해야한다.
- 효율적인 브로트캐스트 알고리즘을 사용하면 메시지 복잡도는 O(n2)가 된다.
Dijkstra's algorithm: oscillations possible
- 링크 비용과 트래픽 볼륨
- 링크 비용이 트래픽 볼륨에 의존할 때, route oscillations이 발생할 수 있다.
- 샘플 시나리오
- 목적지 a로의 라우팅에서, 트래픽이 노드 d,c,e에서 각각 1,e(1보다 작음), 1의 비율로 돌아온다.
- 링크 비용은 방향성이 있으며, 트래픽 볼륨에 따라 달라진다.
Distance vector algorithm
- Bellman-Ford(BF) 방정식을 기반으로 한 거리 벡터 알고리즘(Distance Vector Algorithm)에 대해 설명하고 있다.
- Dynamic 프로그래밍을 이용하여 최소 비용 경로를 계산한다.

- Dx(y): 노드 x에서 노드 y까지의 최소 비용 경로의 비용
- cx,y: 노드 x에서 이웃 노드 v로의 직접 링크 비용
- Dy(y): 노드 v에서 노드 y까지의 최소 비용 경로의 추정 비용
Bellman-Ford Example

Dx(y) : x에서 y까지의 최소 비용 경로의 비용
cx,v: 노드 x에서 이웃 노드 v까지의 직접적인 링크 비용
Dx(y): 노드 v에서 y까지의 추정된 최소 비용 경로의 비용
방정식: Dx(y) = minv{cx,v + Dv(y)}
방정식 해석
- min: 방정식에서 x의 모든 이웃 v를 대상으로 최소값을 계산한다.
- cx,v: 노드 x에서 이웃 노드 v까지의 직접적인 링크 비용
- Dv(y): 이웃 노드 v에서 목적지 y까지의 추정된 최소 비용 경로

Distance Vector Algorithm
주요 개념
- 거리 벡터의 전송
- 일정 시간마다 각 노드는 자신의 거리 벡터(각 목적지까지의 추정 최소 비용)를 이웃노드들에게 전송한다.
- 거리 벡터는 노드가 알고 있는 모든 목적지에 대한 현재 최적 경로 비용을 포함한다.
- 거리 벡터의 수신 및 업데이트
- 노드 x는 이웃으로부터 새로운 거리 벡터를 수신할 때마다, Bellman-Ford 방정식을 사용하여 자신의 거리 벡터를 업데이트한다.
- Dx(y) <- minv{cx,v + Dv(y)}
- 수렴성
- 자연스러운 조건하에서는, 각 노드 x에서 목적지 y까지의 추정된 최소 비용 경로 Dx(y)는 실제 최소 비용 경로 dx(y)로 수렴하게 된다,
Distnace Vector Algorithm
각 노드의 작업 과정
- 기다림(Wait for)
- 각 노드는 지역 링크 비용의 변화 또는 이웃 노드들로부터 메시지 수신을 기다린다.
- 재계산(recompute)
- 이웃으로부터 받은 거리 벡터(DV) 정보를 사용하여 자신의 거리 벡터를 재계산한다.
- 알림(notify)
- 만약 어떤 목적지에 대한 거리 벡터가 변경되었으면, 그 변경 사항을 이웃 노드들에게 알린다.
특성
- 반복적이고 비동기적(iterative, asynchronous)
- 각 지역 반복은 다음의 원인으로 발생한다.
- 지역 링크 비용의 변화
- 이웃으로부터 받은 거리 업데이트 메시지
- 각 지역 반복은 다음의 원인으로 발생한다.
- 분산적이고 자기 정지(distributed, self-stopping)
- 각 노드는 자신의 거리 벡터가 변경되었을 때만 이웃 노드들에게 알린다.
- 이웃 노드들도 필요할 때만 그들의 이웃 노드들에게 알린다.
- 알림을 받지 않으면 아무런 행동을 하지 않는다.
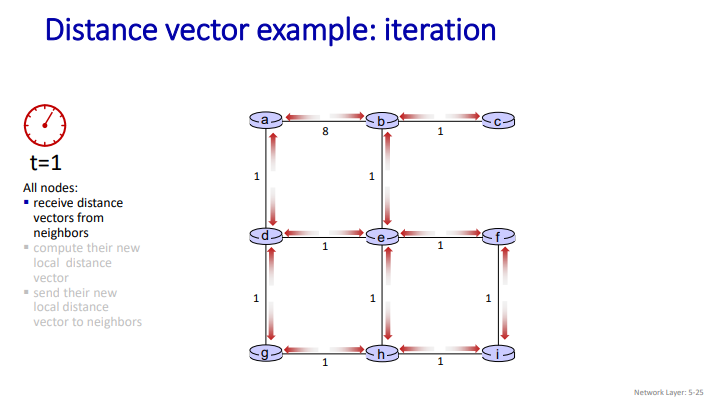
Distance Vector:Example
- 초기 설정
- 모든 노드는 자신과 직접 연결된 이웃 노드들에 대한 거리 벡터를 초기화한다.
- 직접 연결되지 않은 노드들에 대한 경로 비용은 무한대로 설정된다.
- 정보 교환 및 업데이트
- 일정 시간마다 또는 이웃 노드들로부터 거리 벡터를 업데이트를 받을 때마다, 각 노드는 자신의 거리 벡터를 갱신하고 이를 이웃 노드들에게 전송한다.
- Bellman-Ford 방정식을 사용하여 각 노드는 이웃 노드들로부터 받은 정보를 바탕으로 최적 경로를 다시 계산한다.
- 수렴
- 이 과정을 반복하면, 네트워크 내의 모든 노드는 모든 목적지까지의 최적 경로를 찾게 된다.
- 최종적으로 모든 노드는 목적지까지의 최소 비용 경로 정보를 갖게 된다.









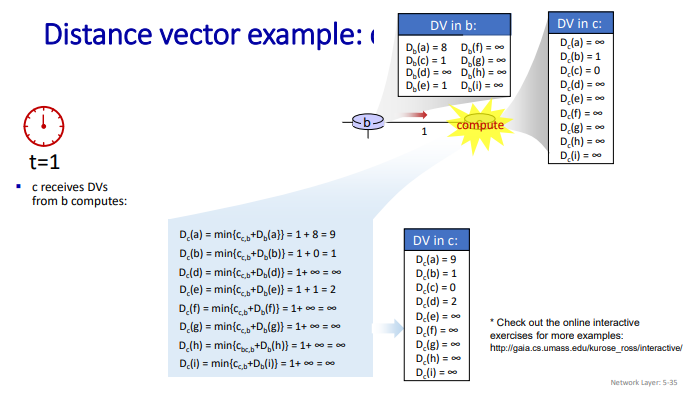


Distance Vector: Link Cost Changes
link cost changes
- node는 local link cost의 변화를 감지한다.
- 변화가 감지되면 routing info를 업데이트하고, local DV를 재계산한다.
- DV가 바뀌면, 이웃들에게 알린다.
- good nnew travels fast
- t0: y가 link-cost 의 변화를 감지한다. 그리고 DV를 업데이트하고 이웃들에게 알린다.
- t1: z는 y로부터 업데이트를 받는다. 그리고는 z의 테이블을 업데이트하고, x에 대한 최소 비용을 계산하고 DV를 이웃들에게 전달한다.
- t2: y는 z의 업데이트를 받고, distance table을 업데이트한다. y의 최소비용은 바뀌지 않는다. 그렇기에 이를 z에게 메시지를 보내지 않는다.

- bad news travels slow
- y는 x로의 cost가 60인 것을 바로 알 수 있다. 허나 z는 x로의 cost가 5 인것으로 알고 있다. 그래서 y는 "노드 x로 가는 나의 새로운 비용은 6이 될 것이다. (노드 z를 경유해서)라고 계산하고, 노드 z에게 새로운 비용 6을 알린다.
- 노드 z는 노드 y를 통해서 노드 x로 가는 경로의 새로운 비용이 6임을 알게 되어, "노드 x로 가는 나의 새로운 비용은 7이 될 것이다. (노드 y를 경유해서)라고 계산하고, 노드 y에게 새로운 비용 7을 알린다.
- 노드 y는 노드 z를 통해 노드 x로 가는 경로의 새로운 비용이 7임을 알게 되어 "노드 x로 가는 나의 새로운 비용은 8이 될 것 이다.(노드 z를 경유해서)라고 계산하고, 노드 z에게 새로운 비용 8을 알린다.
- 이러한 과정이 반복되면서 비용이 계속 증가한다.
- 노드 z는 비용이 8이 되고, 노드 y에게 9를 알림
- 노드 y는 비용이 9가 되고, 노드 z에게 10을 알림
- 계속된다...
Comparison of LS and DV algorithms
message complexity
- LS(Link State)
- n개의 라우터가 있을 때 O(n^2) 메시지가 전송된다.
- DV(Distance Vector)
- 이웃 간의 교환만 필요하다
- 수렴 시간은 상황에 따라 다르다.
수렴 속도(speed of Convergence)
- LS(Link State)
- O(n^2) 알고리즘이며 O(N^2) 메시지가 필요하다.
- 경로의 진동(oscillations)이 발생할 수 있다.
- DV(Distance Vector)
- 수렴 시간은 상황에 따라 다르다.
- 라우팅 루프가 발생할 수 있으며 무한 루프 문제(count-to-infinity problem)가 존재한다.
견고성(Robustness)
- 라우터가 오작동하거나 손상되었을 때 어떻게 되는지에 대한 비교
- LS(Link State)
- 라우터가 잘못된 링크 비용을 광고할 수 있다.
- 각 라우터는 오직 자신의 테이블만 계산한다.
- DV(Distance Vector)
- DV 라우터는 잘못된 경로 비용을 광고할 수 있다.("나는 모든 곳으로 정말 낮은 비용의 경로를 가지고 있다.): black-holing 문제
- 각 라우터의 테이블이 다른 라우터들에 의해 사용되기에 오류가 네트워크를 통해 전파될 수 있다.
Making Routing Scalable
현재까지의 라우티 연구 - 이상적(Idealized)
- 모든 라우터가 동일하다고 가정
- 네트워크가 "평평하다(flat)"고 가정
- 실제로는 그렇지 않음
확장성 문제(Scale: Billions of Destination)
- 모든 목적지를 라우팅 테이블에 저장할 수 없음:
- 라우티 테이블에 모든 목적지를 저장하는 것은 불가능
- 라우팅 테이블 교환이 링크를 압도할 것
- 모든 라우터가 모든 목적지에 대한 정보를 교환하면 네트워크 링크가 과부하될 수 있다.
관리적 자율성(Administrative Autonomy)
- 인터넷: 네트워크의 네트워크
- 인터넷은 여러 네트워크로 구성된 네트워크이다.
- 각 네트워크 관리자는 자신의 네트워크에서 라우팅을 제어하고자 할 수 있음
- 각 네트워크 관리자는 자신이 관리하는 네트워크 내에서 라우팅을 제어하고 싶어할 수 있다.
Internet approach to scalable routing
- 인터넷은 확장 가능한 라우팅을 위해 라우터들을 "자율 시스템(Autonomous Systems, AS)" 또는 "도메인"으로 알려진 영역으로 집계합니다.
Intra-AS (Intra-Domain) 라우팅
- 동일한 AS 내에서의 라우팅
- 네트워크 내에서 라우팅을 의미한다.
- AS 내부의 모든 라우터는 동일한 인트라-도메인 프로토콜을 실행해야 한다.
- 다른 AS에 있는 라우터들은 서로 다른 인트라-도메인 라우팅 프로토콜을 실행할 수 있다.
- 게이트웨이 라우터(Gateway Router)
- 자신의 AS의 "가장자리"에 위치하며, 다른 AS에 있는 라우터와 연결된 링크를 가진다.
Inter-AS(Inter-Domain)
- AS 간 라우팅:
- 여러 AS 간의 라우팅을 의미한다.
- 게이트웨이 라우터는 인트라-도메인 라우팅뿐만 아니라 인터-도메인 라우팅도 수행한다.
Internonnected ASes
포워딩 테이블(Forwarding Table)
- 포워딩 테이블의 구성
- 포워딩 테이블은 Intra-AS routing 및 Inter-AS routing 알고리즘에 의해 구성된다.
- 인트라-AS 라우팅 (Intra-AS Routing)
- AS 내부의 목적지에 대한 항목을 결정합니다.
- 인터-AS 라우팅 (Inter-AS Routing)
- 외부 목적지에 대한 항목을 결정하는 데 인트라-AS 라우팅과 함께 사용됩니다.
라우팅의 예
- AS1, AS2, AS3 간의 라우팅:
- 그림에서 AS1, AS2, AS3이 서로 연결된 모습입니다.
- 각 AS는 내부 라우팅(Intra-AS Routing)을 통해 자체 네트워크 내부의 데이터를 처리하고, 외부 라우팅(Inter-AS Routing)을 통해 다른 AS와의 데이터를 처리합니다.

Inter-AS routing: a role in intradomain forwarding

- AS1 내부의 라우터가 AS1 외부로 향하는 데이터그램을 수신한다.
- 이 라우터는 AS1 내의 게이트웨이 라우터로 패킷을 전달해야 한다. 그러나 어느 게이트웨이 라우터로 보내야 할까?
- AS1 inter-domain routing의 역할
- 목적지 학습
- AS1 인터-도메인 라우팅은 AS2와 AS3를 통해 도달 가능한 목적지를 학습해야 합니다.
- 접근성 정보 전파
- 이 접근성 정보를 AS1 내의 모든 라우터에게 전파해야 합니다.
- 목적지 학습
Inter-AS routing: routing within an AS
AS(Autonomous Systems) 내에서 사용되는 일반적인 라우팅 프로토콜에 대해 설명한다.
- RIP(Routing Information Protocol)
- 고전적인 DV 기반 프로토콜
- 거리 벡터는 30초마다 교환된다.
- 더 이상 사용되지 않음
- EIGRP(Enhanced Interior Gateway Routing Protocol):
- DV 기반 프로토콜
- Cisco 장비에서 주로 사용된다.
- OSPF (Open Shortest Path First)
- 링크 상태 라우팅 프로토콜
- 각 라우터는 전체 네트워크 토폴로지를 알고 있으며, 다익스트라 알고리즘을 사용하여 최단 경로를 계산
- 다양한 링크 비용 메트릭을 지원(대역폭, 지연)
- 보안: 모든 OSPF 메시지는 인증되어 악의적인 침입을 방지
- IS-IS 프로토콜은 ISO 표준이며, OSPF와 본질적으로 동일
OSPF(Open Shortest Path First) routing
주요 특징
- 공개 표준("Open")
- OSPF는 공개적으로 사용할 수 있는 프로토콜
- 클래식 링크 상태 라우팅(classic link-state)
- 링크 상태 광고(Link-State Advertisements)
- 각 라우터는 OSPF 링크 상태 광고를 전체 자율 시스템(AS)의 다른 모든 라우터에게 전송
- 이는 TCP/UDP를 사용하지 않고 직접 IP를 통해 이루어진다.
- 다양한 링크 비용 매트릭 지원
- OSPF는 대역폭, 지연 시간 등 다양한 링크 비용 메트릭을 지원한다.
- 전체 토폴로지 인식
- 각 라우터는 네트워크의 전체 토폴로지를 알고 있으며, 다익스트라 알고리즘을 사용하여 포워딩 테이블을 계산한다.
- 링크 상태 광고(Link-State Advertisements)
- 보안(Security)
- 모든 OSPF 메시지는 인증되어 악의적인 침입을 방지한다.
Hierarchical OSPF
- 두 계층 구조(Two-Level Hierarchy)
- 로컬 영역(Local Area)
- 백본(Backbone)
- 링크 상태 광고(Link-State Advertisements)
- 링크 상태 광고는 해당 영역 내에서만 또는 백본 내에서만 플러딩(전송)된다.
- 노드의 토폴로지 인식
- 각 노드는 해당 영역의 상세한 토폴로지를 알고 있으며, 다른 목적지로 가는 방향만을 알고 있다.
구성 요소
- 로컬 라우터(Local Routers)
- LS 플러딩: 링크 상태 광고는 해당 영역 내에서만 플러딩된다.
- 라우팅 계산: 영역 내에서의 라우팅을 계산
- 패킷 포워딩: 영역 외부로 가는 패킷은 영역 경계 라우터를 통해 포워딩된다.
- 영역 경계 라우터(Area Border Routers)
- 자신의 영역 내 목적지로의 거리를 요약하여 백본에 광고한다.
- 백본 라우터(Backbone Routers)
- 백본 내에서 OSPF를 실행
- 백본은 전체 네트워크의 중심 역할을 한다.
- 경계 라우터(Boundary Routers)
- 다른 AS와 연결된다.
routing among ISPs: BGP
Internet inter-AS routing: BGP(Border Gateway Protocol)
- BGP 개요
- BGP(Border Gateway Protocol): 사실상의 inter-domain 라우팅 프로토콜이다.
- "인터넷을 하나로 묶는 접착제"라고 불린다.
- BGP(Border Gateway Protocol): 사실상의 inter-domain 라우팅 프로토콜이다.
- BGP의 역할
- 서브넷이 자신의 존재와 도달할 수 있는 목적지를 인터넷의 다룬 부분에 광고할 수 있도록 한다.
- "나는 여기 있고, 내가 도달할 수 있는 곳과 그 방법은 이것이다."
- 서브넷이 자신의 존재와 도달할 수 있는 목적지를 인터넷의 다룬 부분에 광고할 수 있도록 한다.
- BGP가 각 AS에 제공하는 기능
- eBGP(External BGP)
- 이웃 AS로부터 서브넷 도달 가능 정보를 얻는다.
- iBGP(Internet BGP)
- 도달 가능 정보를 모든 AS 내부 라우터에게 전파
- 경로 결정
- 도달 가능 정보와 정책에 기반하여 다른 네트워크로의 "좋은" 경로를 결정
- eBGP(External BGP)
eBGP, iBGP connections

BGP basics
BGP Session
- 두 개의 BGP 라우터("peer")가 반영구적인 TCP 연결을 통해 BGP 메시지를 교환한다.
- 서로 다른 목적지 네트워크 프리픽스(destination network prefixes)로 가는 경로를 광고한다.
- BGP는 "경로 벡터(path vector)" 프로토콜이다.
- 예: AS3 게이트웨이 3a가 AS2 게이트웨이 2c에게 path AS3, X를 광고할 때, AS3는 AS2에게 X로 가는 데이터그램을 전달할 것을 약속한다.

Path attributes and BGP routes
- BGP advertised route: prefix + attributes
- prefix: 광고되는 목적지를 나타낸다.
- 중요한 두 가지 속성
- AS-PATH: 접두사 광고가 통과한 자율 시스템(AS)의 목록
- NEXT-HOP: 다음 홉 AS로 가는 특정 내부 AS 라우터를 나타낸다.
- policy-based routing
- 경로 광고를 수신하는 게이트웨이는 수입 정책(import policy)을 사용하여 경로를 수락하거나 거부한다.
- e.g. AS Y를 통해 절대 라우팅하지 않도록 설정
- AS 정책은 또한 다른 인접 AS에 경로를 광고할지 여부를 결정
- 경로 광고를 수신하는 게이트웨이는 수입 정책(import policy)을 사용하여 경로를 수락하거나 거부한다.
BGP path advertisement

- AS2 라우터 2c가 경로 광고를 수신
- AS2의 라우터 2c는 AS3의 라우터 3a로부터 AS3, X 경로 광고를 eBGP를 통해 수신한다.
- 이 광고는 AS3가 목적지 X로 가는 경로를 가지고 있음을 나타낸다.
- AS2 정책에 따라 경로 수락 및 전파
- AS2 정책에 따라, AS2의 라우터 2c는 AS3, X 경로를 수락하고, iBGP를 통해 이 경로를 모든 AS2 라우터에게 전파한다.
- 이로써 AS2 내부의 모든 라우터는 AS3, X 경로를 알게된다.
- AS2 정책에 따라 경로 광고
- AS2 정책에 따라, AS2의 라우터 2a는 eBGP를 통해, AS2, AS3, X 경로를 AS1의 라우터 1c에게 광고한다.
- 이제 AS1도 X로 가는 경로를 알게 된다.

gateway router는 destination에 대한 multiple paths에 대해 학습할 것이다.
- AS1의 게이트웨이 라우터 1c는 AS2의 라우터 2a로부터 AS2, AS3, X 경로를 학습한다.
- 또한, AS1의 게이트웨이 라우터 1c는 AS3의 라우터 3a로부터 직접 AS3, X 경로를 학습한다.
- 정책 기반 경로 선택: AS1의 정책에 따라, 게이트웨이 라우터 1c는 AS3, X 경로를 선택하고, iBGP를 통해 AS1 내의 모든 라우터에게 광고한다.
BGP messages
- BGP(Border Gateway Protocol) 메시지는 peer 간에 TCP 연결을 통해 교환된다. 이러한 메시지는 BGP 피어 간의 경로 정보 교환과 연결 상태를 유지하는 데 사용된다.
- BGP 메시지 유형
1. OPEN: - 기능: 원격 BGP peer에 TCP 연결을 열고, 발신 BGP 피어를 인증한다. - 용도: BGP 세션을 초기화하고 연결을 설정한다.
2. UPDATE: - 기능: 새로운 경로를 광고하거나 기존 경로를 철회한다. - 용도: 경로 정보를 갱신하고 BGP 피어 간에 최신 경로 정보를 전달한다.
3. KEEPALIVE: - 기능: 업데이트가 없는 경우에도 연결을 유지한다. 또한 OPEN 요청을 확인(ACK)한다. - 용도: BGP 세션이 살아있음을 확인하고, 정기적으로 연결 상태를 점검한다.
4. NOTIFICATION - 기능: 이전 메시지에서 발생한 오류를 보고하거나 연결을 종료하는 데 사용 - 용도: 오류 발생 시 이를 보고하고, 필요 시 연결을 종료하여 문제를 해결
BGP path advertisement
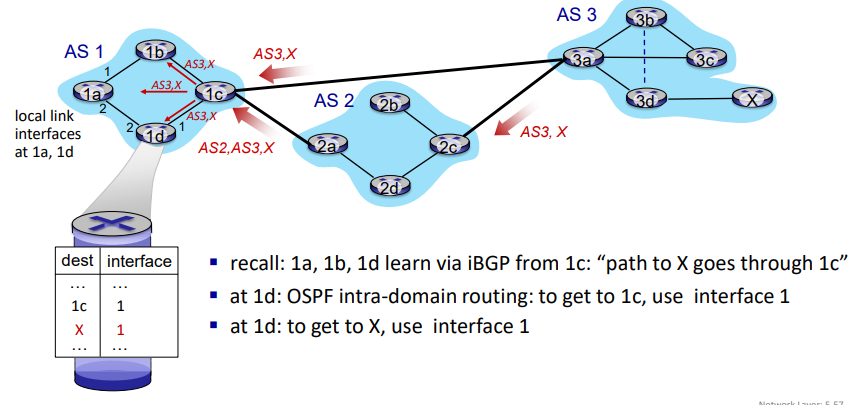
- AS1의 라우터 1a, 1b, 1d는 iBGP를 통해 라우터 1c로부터 "목적지 X로 가는 경로는 1c를 거쳐 간다"는 정보를 학습하낟.
- 라우팅 테이블
- AS1의 라우터 1d는 라우팅 테이블에서 목적지 X로 가기 위해 인터페이스 1을 사용해야 함을 알게 된다.
- 이 정보는 OSPF intra-domain 라우팅을 통해 라우터 1d에게 전달된다.

- 라우팅 테이블
- AS1의 라우터 1d
- AS1의 라우터 1d는 라우팅 테이블에서 목적지 X로 가기 위해 인터페이스 1을 사용해야 함을 알게 된다.
- 이 정보는 OSPF intra-domain 라우팅을 통해 라우터 1d에게 전달된다.
- AS1의 라우터 1a
- OSPF 인트라-도메인 라우팅을 통해 목적지 1c로 가기 위해 인터페이스 2를 사용해야한다.
- 목적지 x로 가기 위해서는 1c를 거쳐야 하므로 인터페이스 2를 사용한다.
- AS1의 라우터 1d
Why different Intra-, Inter- AS routing?
Policy
- inter-AS:
- 관리자는 네트워크를 통해 트래픽이 어떻게 라우팅되는지, 누가 라우팅하는지에 대한 제어를 원한다.
- 다수의 관리자가 존재하기에 각 AS의 정책이 중요하다.
- intra-AS
- 단일 관리자에 의해 관리되므로 정책의 중요성이 상대적으로 적다.
Scale
- 계층적 라우팅:
- 계층적 라우팅은 라우팅 테이블 크기를 줄이고, 업데이트 트래픽을 감소시킨다.
- AS 내부에서는 네트워크를 더 작은 단위로 나눌 수 있어 효율적이다.
성능(Performance)
- Intra-AS
- 성능에 집중할 수 있다.
- AS 내부에서는 트래픽이 최적의 경로를 따라 이동하도록 성능 최적화가 가능하다.
- Inter-AS
- 정책이 성능보다 우선한다.
- 다른 AS와의 관계, 계약 조건 등이 성능보다 중요한 역할을 한다.
BGP: achieving policy via advertisements

- ISP는 고객 네트워크로의 트래픽만 라우팅하려고 한다.
- 다른 ISP 간의 중계 트래픽을 전달하고 싶어하지 않는다.
- 이는 일반적인 "실제" 정책이다.
단계별 설명
- 광고 경로
- A는 경로 A, w를 B와 C에 광고한다.
- A는 자신이 w로 가는 경로를 가지고 있음을 B와 C에 알린다.
- A는 경로 A, w를 B와 C에 광고한다.
- 정책 결정:
- B는 경로 B, A, w를 C에 광고하지 않기로 선택한다.
- B는 C,B,A,w 경로에 대한 "수익"을 얻지 못한다. C,A,w는 B의 고객이 아니기 때문이다.
- 따라서 C는 C,B,A,w 경로를 알지 못하게 된다.
- B는 경로 B, A, w를 C에 광고하지 않기로 선택한다.
- 경로 선택:
- C는 경로 C, A, w를 통해 w로 가는 경로를 선택합니다 (B를 사용하지 않음)
- C는 A를 통해 w로 가는 경로를 알고 있으며, B를 통해 가는 경로를 사용하지 않습니다.
- C는 경로 C, A, w를 통해 w로 가는 경로를 선택합니다 (B를 사용하지 않음)
BGP: achieving policy via advertisements(more)

- A,B,C: 제공자 네트워크(Provider Networks)
- x,y,z: 제공자 네트워크의 고객(Customer Networks)
- x: 두 네트워크에 연결된 듀얼 홈드(Dual-Homed)고객
정책(Policy)
- ISP는 다른 ISP 간의 중계 트래픽을 전달하지 않고 고객 네트워크로의 트래픽만 라우팅하려고 한다.
- 이는 일반적인 "실제" 정책이다.
- x가 B에서 C로 가는 경로를 광고하지 않음
- x는 B에서 C로 가는 트래픽을 라우팅하고 싶지 않습니다.
- 따라서 x는 B에서 C로 가는 경로를 광고하지 않습니다.
- 결과적으로, B는 x를 통해 C로 가는 경로를 알지 못하게 된다.
BGP route selection
- BGP 라우터는 목적지 AS로 가는 여러 경로에 대해 학습할 수 있으며, 다음 기준을 기반으로 최적의 경로를 선택한다.
- 로컬 우선순위 값 속성(Local Preference Value Attribute): 정책 결정(Policy Decision)
- 네트워크 관리자가 특정 경로에 우선순위를 부여하는 값
- 정책 결정에 따라 우선순위가 높은 경로를 선택한다.
- 가장 짧은 AS-PATH(Shortest AS-PATH)
- 경로에 포함된 AS의 수가 가장 적은 경로를 선택한다.
- 일반적으로 가장 적은 수의 AS를 통과하는 경로가 더 빠르고 효율적이다.
- 가장 가까운 NEXT-HOP 라우터(Closest NEXT-HOP Router): 핫 포테이토 라우팅(Hot Potato Routing)
- 다음 홉 라우터가 가장 가까운 경로를 선택한다.
- 트래픽을 빠르게 외부 네트워크로 전달하는 것을 목표로 한다.
- 추가 기준(Additional Criteria)
- 위의 기준으로 경로를 선택할 수 없을 때 사용되는 추가적인 기준이다.
- 이는 다양한 네트워크 조건에 따라 다를 수 있다.
SDN(Software defined networking)
- 인터넷 네트워크 계층의 전통적인 구현 방식
- 분산된 라우터 기반 제어(Distributed, Per-Router Control)
- 전통적으로 인터넷 네트워크 계층은 분산된 각 라우터에 의해 제어되었다.
- 단일체(monolithic) 라우터
- 스위칭 하드웨어를 포함하고, 인터넷 표준 프로토콜(IP, RIP, IS-IS, OSPF, BGP 등)의 고유 구현을 실행한다.
- 전용 라우터 운영 체제(e.g. Cisco IOS)에서 작동한다.
- 미들박스(Middleboxes)
- 방화벽, 로드 밸런서, NAT 박스 등 다양한 네트워크 계층 기능을 수행하는 장치들이다.
- 분산된 라우터 기반 제어(Distributed, Per-Router Control)
- 2005년경: 네트워크 제어 평면 재고에 대한 새로운 관심
- 네트워크 제어 평면을 재고하려는 새로운 관심이 일어났다.
- 이는 네트워크의 유연성과 효율성을 높이기 위한 노력의 일환
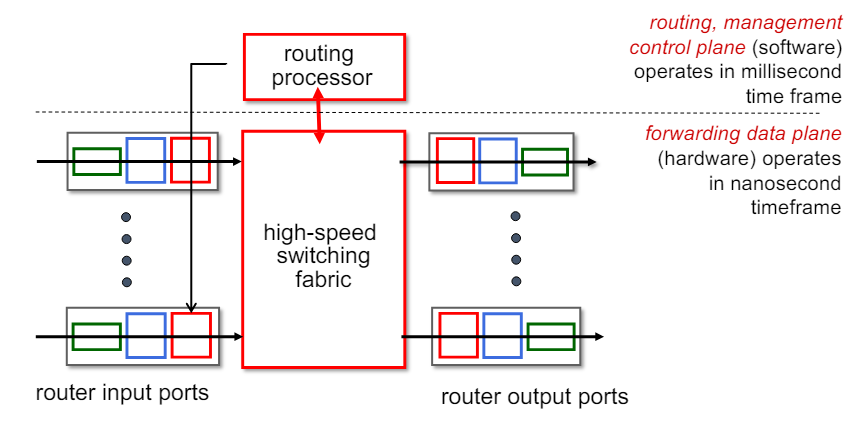
Pre-router control plane

개별 라우팅 알고리즘 구성 요소
- 각 라우터마다 개별 라우팅 알고리즘 구성 요소가 존재한다.
- 이 구성 요소들은 제어 평면에서 상호 작용하여 포워딩 테이블을 계산한다.
구성 요소 및 동작 방식
- 제어 평면(Control Plane)
- 라우팅 알고리즘이 실행되는 영역
- 각 라우터는 제어 평면에서 라우팅 정보를 계산하고, 이를 바탕으로 포워딩 테이블을 작성한다.
- 데이터 평면(Data Plane)
- 패킷이 실제로 전달되는 영역
- 포워딩 테이블의 값을 기반으로 패킷을 적절한 출력 포트로 전달한다.
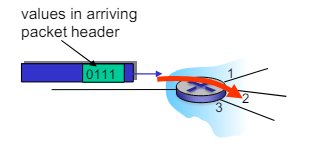
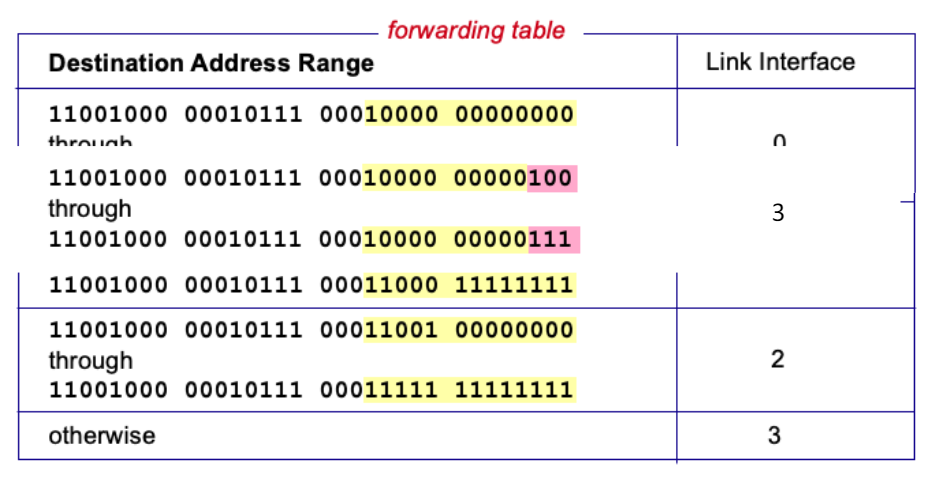
- 포워딩 테이블(Forwarding Table)
- 도착하는 패킷 헤더의 값을 기반으로 출력 포트를 결정한다.
- e.g. 도착 패킷의 헤더 값이 0111 일 때 출력 포트가 2번으로 설정되어 있으면, 패킷은 2번 포트로 전달된다.
Software-Defined Networking(SDN) control plane
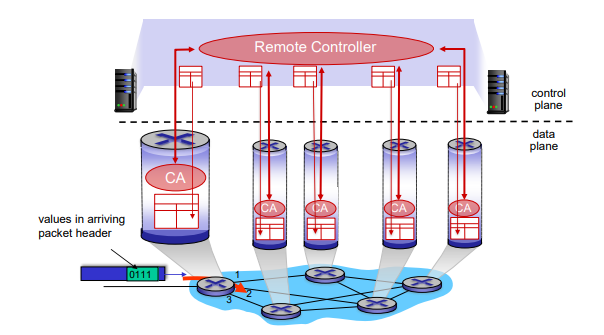
SDN(Software-Defined Networking)
- 전통적인 네트워크와 달리 SDN에서는 중앙 집중식 컨트롤러가 네트워크 제어를 담당한다.
- 컨트롤러는 네트워크 전반의 라우팅 결정을 내리고, 각 라우터에 포워딩 테이블을 설치한다.
구성 요소 및 동작 방식
- 리모트 컨트롤러(Remote Controller)
- 네트워크 전반을 제어하는 중앙 집중식 장치
- 네트워크 상태와 요구에 따라 포워딩 테이블을 계산한다.
- 각 라우터에 포워딩 테이블을 설치한다.
2. **포워딩 테이블 설치** - 리모트 컨트롤러가 계산한 포워딩 테이블을 각 라우터에 설치한다. - 라우터는 컨트롤러로부터 받은 포워딩 테이블을 사용하여 패킷을 전달한다.
3. **제어 평면(Control Plane) 및 데이터 평면(Data Plane)** - 제어 평면: 리모트 컨트롤러가 네트워크 전반의 라우팅 결정을 내리는 영역이다. - 데이터 평면: 라우터가 포워딩 테이블을 사용하여 패킷을 전달하는 영역이다.
4. **CA(Control Agent)** - 각 라우터에 있는 제어 에이전트로, 리모트 컨트롤러와 통신하여 포워딩 테이블을 설치받고 실행한다.
Software Defined Networking(SDN)
논리적으로 중앙 집중화된 제어 평면
- 쉬운 네트워크 관리
- 라우터의 잘못된 구성 방지: 중앙에서 일관된 제어가 가능하므로, 각 라우터의 개별적인 구성 실수를 방지할 수 있다.
- 트래픽 흐름의 유연성: 중앙 집중식 제어로 인해 트래픽 흐름을 더 유연하게 관리할 수 있다.
- 테이블 기반 포워딩(Table-Based Forwarding)
- OpenFlow API: 테이블 기반 포워딩을 통해 라우터를 "프로그래밍"할 수 있다.
- 중앙 집중식 프로그래밍:
- 테이블을 중앙에서 계산하고 각 라우터에 분배하는 방식으로, 더 쉽게 관리할 수 있다.
- 분산 프로그래밍
- 각 라우터마다 분산된 알고리즘(프로토콜)을 구현하여 테이블을 계산하는 방식은 더 어렵고 복잡하다.
- 오픈 (비동점적) 제어 평면 구현
- 혁신 촉진
- 개방형 표준을 통해 다양한 혁신이 이루어질 수 있다.
- "1000개의 꽃이 피게 하라"는 철학을 반영하여, 다양한 기술과 아이디어가 자유롭게 발전할 수 있도록 한다.
- 혁신 촉진
Traffic engineering: difficult with traditional routing

질문과 대답
- Q: 네트워크 운영자가 u에서 z로 가는 트래픽이 u-v-w-z 경로를 따르기를 원한다고 가정하자. 대신 u-x-y-z 경로를 피하고자 한다.
- A: 트래픽 라우팅 알고리즘이 경로를 재계산하도록 링크 가중치를 다시 정의해야 한다.(또는 새로운 라우팅 알고리즘이 필요할 수도 있다.)
제어의 한계
- 전통적인 라우팅에서 링크 가중치는 트래픽 엔지니어링을 제어할 수 있는 유일한 "조절기"이다.
- 이는 라우팅 경로를 세밀하게 제어하는 데 충분하지 않다.
Traffic engineering: difficult with traditional routing

질문과 대답
- Q. 네트워크 운영자가 u에서 z로 가는 트래픽을 u-v-w-z와 u-x-y-z 경로로 분할하고자 한다면(로드 밸런싱) 어떻게 해야하는가?
- A. 전통적인 라우팅 방식에서는 이를 할 수 없으며, 새로운 라우팅 알고리즘이 필요하다.
Traffic engineering: difficult with traditional routing

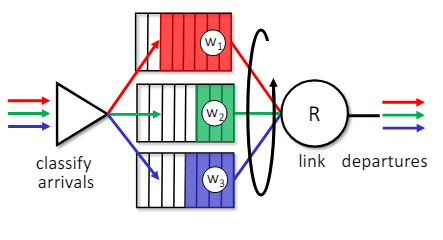
질문과 대답
- Q. w가 z로 가는 파란색 트래픽과 빨간색 트래픽을 다르게 라우팅하려면 어떻게 해야할까?
- A. 목적지 기반 포워딩과 링크 상태(LS) 및 거리 벡터(DV) 라우팅으로는 이를 할 수 없다.
Software defined networking(SDN)

- 일반화된 "흐름 기반" 포워딩(Generalized "Flow-Based" Forwarding)
- e.g. OpenFlow
- 네트워크 스위치가 흐름 단위로 트래픽을 처리한다.
- 각 흐름에 대해 포워딩 규칙을 설정하고, 이러한 규칙은 중앙 집중식 컨트롤러에 의해 관리된다.
- 제어 평면과 데이터 평면의 분리(Control Plane and Data Plane Separation)
- 제어 평면(Control Plane): 네트워크 트래픽의 경로를 결정하고, 포워딩 규칙을 설정하는 논리적 영역
- 데이터 평면(Data Plane): 실제로 데이터 패킷을 전달하는 물리적 영역
- 이 두 영역을 분리함으로써 네트워크의 유연성과 관리 효율성을 높인다.
- 데이터 평면 스위치 외부의 제어 평면 기능(Control Plane Fucntions External to Data-Plane Switches)
- 네트워크의 제어 기능이 데이터 평면 스위치 외부에 위치한 중앙 집중식 컨트롤러에 의해 수행된다.
- 리모트 컨트롤러(Remote Controller): 네트워크 전체의 제어 기능을 중앙에서 관리하며, 포워딩 규칙을 계산하고 배포한다.
- 프로그래밍 가능한 제어 어플리케이션(Programming Control Applications)
- 라우팅(Routing), 접근 제어(Access Control), 로드 밸런싱(Load Balancing) 등
- 중앙 컨트롤러에서 실행되는 다양한 제어 어플리케이션이 네트워크의 다양한 요구를 충족시킨다.
- 네트워크 관리자가 필요에 따라 제어 어플리케이션을 프로그래밍하여 네트워크 동작을 최적화할 수 있다.
Software defined networking(SDN)
데이터 평면 스위치(Data-Plane Switches)
- 역할 및 특징
- 빠르고 간단한 상용 스위치(Fast, Simple, Commodity Switches)
- 일반적인 하드웨어에서 구현되는 데이터 평면 포워딩을 수행한다.
- 일반화된 데이터 평면 포워딩(Generalized Data-Plane Forwarding)
- 특정 프로토콜에 구애받지 않고 다양한 유형의 트래픽을 처리할 수 있다.
- e.g. 섹션 4.4에서 설명된 방식
- 빠르고 간단한 상용 스위치(Fast, Simple, Commodity Switches)
- 흐름 테이블(Flow Table)
- 컨트롤러 감독 하에 계산 및 설치(Computed and Installed Under Controller Supervision)
- 중앙 집중식 컨트롤러가 각 스위치에 설치할 흐름 테이블을 계산하고, 이를 설치한다.
- 컨트롤러 감독 하에 계산 및 설치(Computed and Installed Under Controller Supervision)
- API 및 프로토콜
- 테이블 기반 스위치 제어를 위한 API
- e.g. OpenFlow
- 제어 가능한 것과 그렇지 않은 것을 정의
- 컨트롤러와의 통신을 위한 프로토콜
- e.g. OpenFLow
- 스위치와 컨트롤러 간의 통신을 위한 표준 프로토콜
- 테이블 기반 스위치 제어를 위한 API

Software Defined Networking(SDN)

SDN 컨트롤러(SDN Controller, Network OS)
- 네트워크 상태 정보 유지(Maintain Network State Information)
- SDN 컨트롤러는 네트워크의 전체 상태 정보를 유지합니다.
- 네트워크의 트래픽 흐름, 링크 상태, 스위치 상태 등의 정보를 중앙에서 관리한다.
- 북향 API를 통한 네트워크 제어 어플리케이션과의 상호 작용(Interacts with Network Control Applications "Above" via Northbound API)
- 네트워크 제어 어플리케이션(Network-Control Application)
- 라우팅, 접근 제어, 로드 밸런싱 등의 어플리케이션이 포함된다.
- 북향 API(Northbound API)
- SDN 컨트롤러와 네트워크 제어 어플리케이션 간의 통신을 위한 인터페이스이다.
- 네트워크 제어 어플리케이션(Network-Control Application)
- 남향 API를 통한 네트워크 스위치와의 상호 작용(Interacts with Network Swithches "Below" via Southbound API)
- SDN 제어 스위치(SDN-Controlled Switches)
- SDN 컨트롤러의 명령에 따라 작동하는 네트워크 스위치이다.
- 남향 API
- SDN 컨트롤러와 네트워크 스위치 간의 통신을 위한 인터페이스이다.
- SDN 제어 스위치(SDN-Controlled Switches)
- 분산 시스템으로 구현(Implemented as Distributed System)
- 성능(Performance)
- 네트워크의 성능을 최적화하기 위해 SDN 컨트롤러는 분산 시스템으로구현된다.
- 확장성(Scalability)
- 네트워크 규모에 따라 쉽게 확장할 수 있도록 설계된다.
- 장애 내성(Fault-Tolerance)
- 네트워크 장애에 대한 내성을 갖추고 있다.
- 견고성(Robustness)
- 네트워크의 견고성을 유지하기 위해 분산 시스템으로 운영된다.
- 성능(Performance)
Software Defined Networking

네트워크 제어 어플리케이션
- Brains of Control
- 네트워크 제어 어플리케이션은 제어 기능을 구현하는 핵심 요소이다.
- SDN 컨트롤러가 제공하는 하위 수준의 서비스와 API를 사용하여 네트워크 제어 기능을 수행한다.
- 이러한 어플리케이션은 라우팅, 접근 제어, 로드 밸런싱 등 다양한 제어 작업을 처리한다.
- 언번들된(Unbundled)
- 네트워크 제어 어플리케이션은 라우팅 벤더나 SDN 컨트롤러와 별개로 제 3자에 의해서 제공될 수 있다.
- 이는 네트워크 관리자가 특정 벤더에 종속되지 않고 다양한 어플리케이션을 선택하여 사용할 수 있게 한다.
Components of SDN controller
'학교수업 > 컴퓨터망' 카테고리의 다른 글
| Chapter7: Wireless and Mobile Networks (4) | 2024.07.14 |
|---|---|
| Chapter6: The Link Layer and LANs (0) | 2024.07.12 |
| Chapter4: Network Layer-Data Plane (0) | 2024.07.04 |
| Chapter3: Transport Layer-2 (0) | 2024.07.04 |
| Chapter3: Transport Layer (0) | 2024.07.03 |





























































{kind=link}